Cursor: 持续优化我们的 Agent Harness
Cursor 如何像打磨软件产品一样打磨 Agent Harness——从上下文窗口管理、A/B 实验、工具可靠性,到模型定制与多智能体未来。
标题:持续优化我们的 Agent Harness
原文作者:Stefan Heule
简介:Cursor 如何像打磨软件产品一样打磨 Agent Harness——从上下文窗口管理、A/B 实验、工具可靠性,到模型定制与多智能体未来。
原文链接:https://cursor.com/blog/continually-improving-agent-harness
我们打造 Cursor agent harness 的方式,和我们打磨任何一款有野心的软件产品如出一辙。大量工作由愿景驱动:我们先对理想的 agent 体验形成判断,再提出假设、设计实验来验证,并通过评测和真实使用中的定量与定性信号持续迭代。这一过程依赖完善的线上与线下监控体系,才能判断一次改动是否真的让 harness 变得更好。
每当我们提前拿到新模型的内测资格,上述所有方法就会同时汇聚。我们会花数周时间针对该模型的优势和特性深度定制 harness,直到同一个模型在我们精心调校的 harness 加持下,明显更快、更聪明、更高效。
偶尔,我们会发现阶跃式的突破性改进。但更多时候,提升 harness 靠的是近乎偏执地堆叠一个个小优化,它们叠加在一起,才让 agent 在构建软件时变得更出色。
上下文窗口的演进
与大语言模型交互的核心,是上下文窗口。当你要求 agent 构建某样东西时,上下文窗口以系统提示词和工具描述开头,其后是当前对话状态,最后是用户的请求。
我们填充和管理这个窗口的方式,在 Cursor 的发展历程中已经发生了显著变化。
2024 年底我们首次开发编码 agent 时,模型自主选择上下文的能力还很弱,我们投入了大量上下文工程工作来构建护栏——例如,每次编辑后向 agent 推送 lint 和类型错误,当它读取的行数不足时重写其文件读取请求,甚至限制单次对话中工具调用的最大次数。
我们还在每次会话开始时提供大量静态上下文,始终可供 agent 使用。在不同阶段,这些静态上下文包括代码库的目录结构、与查询语义匹配的代码片段,以及用户手动附加文件的压缩版本。
如今,这些做法大多已成历史。
我们仍然保留一些有用的静态上下文(例如操作系统信息、git 状态、当前及最近查看的文件),但我们已经顺应模型能力的提升,拆除了大量护栏,转而提供更多动态上下文——agent 可以在工作过程中按需拉取。在此前的一篇文章中,我们深入探讨了动态上下文发现背后的若干技术,其中许多已被其他编码 agent 所采用。我们现在的工作重心,在于为 agent 提供更多动态拉取上下文、与外部世界交互的方式。
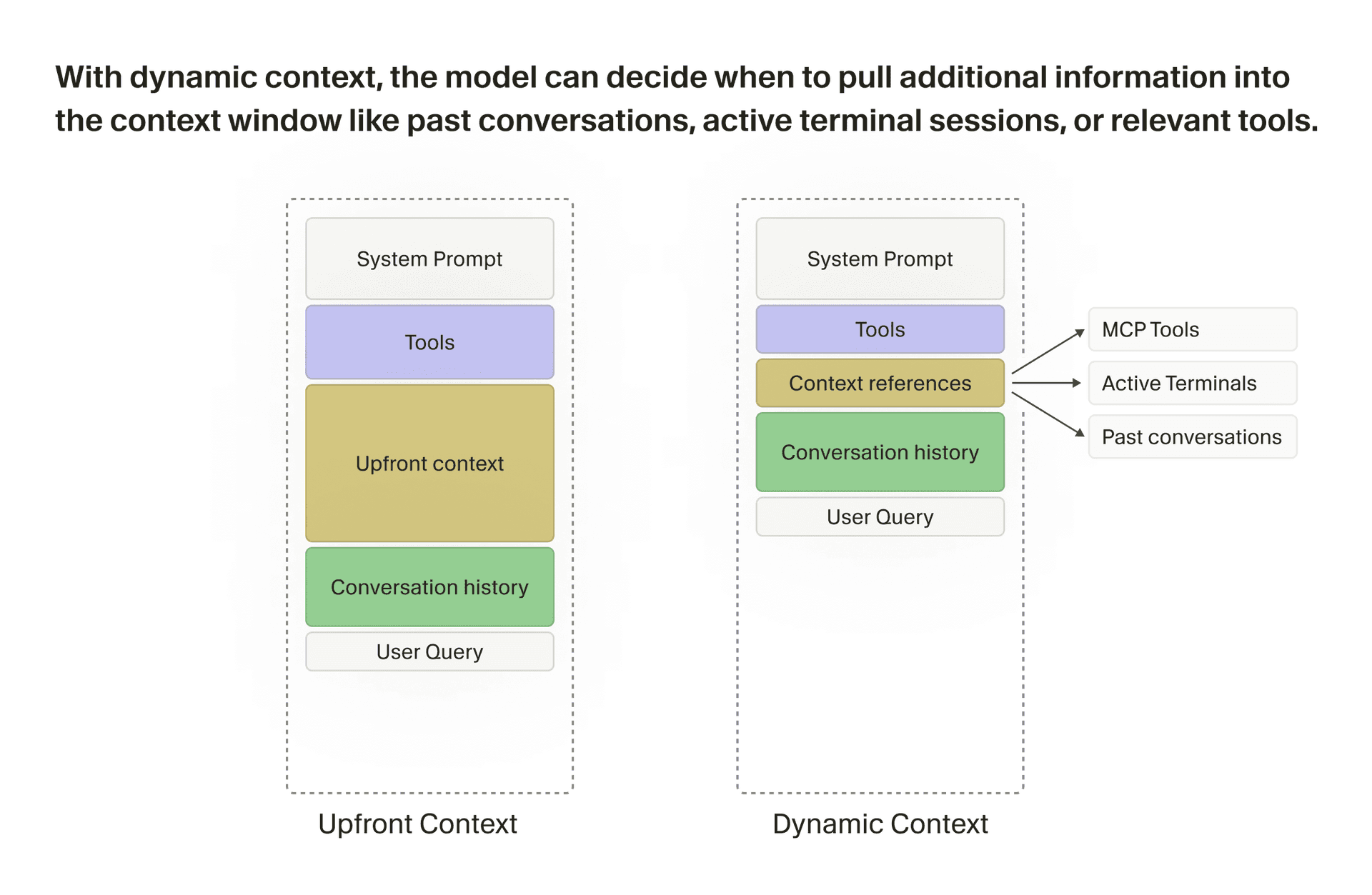
借助动态上下文,模型可以自主决定何时将历史对话、活跃终端会话或相关工具等额外信息拉入上下文窗口。
评估 Harness 变更的两种方式
Harness 与模型共同决定 agent 的质量,但"质量好"难以精确定义。为了锚定它,我们构建了多层度量体系。
我们在维护公开基准测试的同时,也自主运营评测套件 CursorBench,它能给出快速、标准化的质量读数,并支持跨时间维度的横向对比。但即使是最好的基准测试也只是真实使用的近似,完全依赖它会让我们错失重要信号。
因此,我们还会运行线上实验——将两个或多个 harness 变体并行部署,对真实用户进行 A/B 测试。我们通过多种指标衡量 agent 质量:延迟、token 效率、工具调用次数、缓存命中率等,这些指标具有方向性参考价值,但仍无法直接回答 agent 是否真正完成了任务这一更模糊也更重要的问题。我们通过两种方式来衡量后者。
第一种是 agent 生成代码的留存率(Keep Rate)。对于 agent 提出的一组代码变更,我们追踪在固定时间间隔后,有多少比例仍留存在用户的代码库中。这使我们能够了解用户需要手动调整 agent 输出、或需要反复迭代让 agent 修复问题的情况——这些都说明 agent 的初始响应质量不够高。
第二种是用语言模型读取用户对 agent 初始输出的回复,从语义层面判断用户是否满意。用户继续开始下一个功能,是 agent 完成任务的强烈正向信号;用户粘贴一段报错堆栈,则是可靠的负向信号。
有时,线上实验的结论会让我们放弃一个看似有前景的想法。在一次实验中,我们尝试用更昂贵的模型进行上下文摘要,结果发现它对 agent 质量的提升微乎其微,不值得额外付出的成本。
追踪与修复质量退化
随着模型和功能的增加,harness 像任何软件一样,会变得更加复杂,潜在状态也越来越多。随之而来的是更大的 bug 滋生面——其中许多只有在规模化运行时才能被发现。
Agent 的工具是 bug 最集中的领域之一,工具调用出错对 Cursor 的一次会话可能造成极大损害。虽然 agent 通常能够自我纠正,但错误会留存在上下文中,既浪费 token,又造成"上下文腐败"(context rot)——错误的积累会逐渐降低模型后续决策的质量。
有时,一次工具调用失败甚至会让 agent 完全卡住或失控。工具调用量和错误率等指标虽然不直接衡量 agent 是否完成了任务,但它们是指向更深层问题的风向标。
任何未知错误都代表 harness 中的一个 bug,我们如此对待。但许多错误是"预期内"的,例如模型偶尔提出不正确的编辑,或试图读取一个不存在的文件。我们将这些预期错误按原因分类:InvalidArguments 和 UnexpectedEnvironment 捕获模型错误和上下文窗口中的矛盾,ProviderError 捕获 GenerateImage、WebSearch 等工具的供应商中断。
此外还有 UserAborted、Timeout 等几个分类,共同涵盖了大多数预期错误。
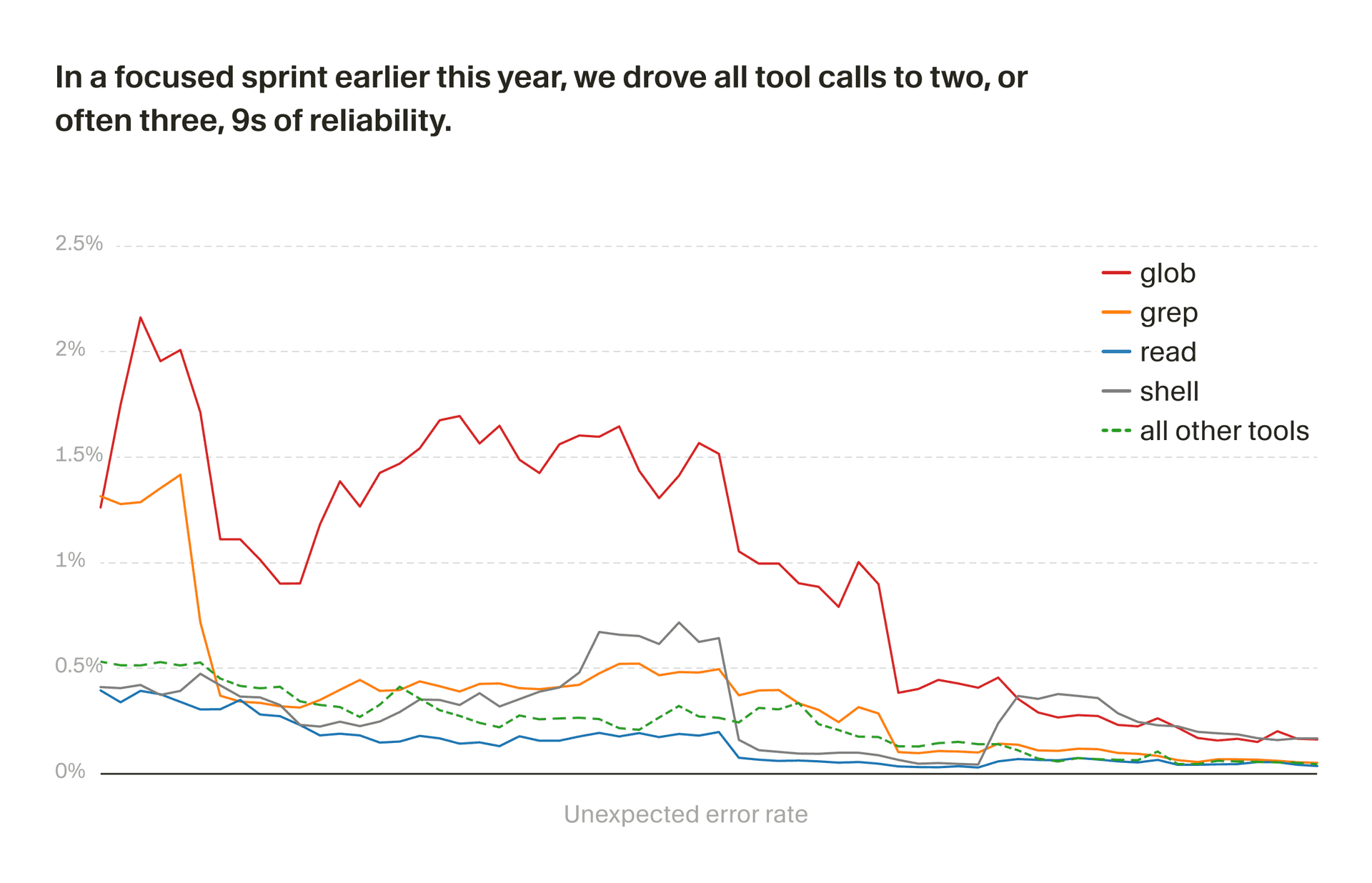
在今年初的一次专项冲刺中,我们将所有工具调用的可靠性提升至至少 2 个 9,通常达到 3 个 9。
我们基于这些指标设置告警,以捕获进入生产环境的重大退化。由于未知错误始终是 bug,每当任何工具的未知错误率超过固定阈值时,我们就会触发告警。但要判断预期错误究竟是 harness 中的 bug 还是正常行为,有时并不容易。
例如,grep 搜索超时,可能是工具本身的性能问题,也可能只是代码库过于庞大、模型构造了一个低效查询。为此,我们设置了异常检测告警:当预期错误显著超出基线时触发。基线按工具和模型分别计算,因为不同模型犯工具调用错误的频率可能不同。
我们还每周运行一个配备了专项 skill 的自动化任务,让模型学会在日志中检索,发现新出现或近期激增的问题,并在积压工单中创建或更新调查记录。我们大量借助 Cloud Agent 同时启动多个问题的修复,甚至可以直接从 Linear 触发。
这一过程是我们为 agent harness 构建自动化"软件工厂"的一部分。在今年初的一次专项冲刺中,我们将未知工具调用错误下降了一个数量级。
为不同模型定制 Harness
我们所有的 harness 抽象层都与模型无关,并且可以为每个支持的模型进行深度定制。例如,OpenAI 的模型经训练使用基于 patch 的格式来编辑文件,而 Anthropic 的模型则基于字符串替换。两种模型都可以使用任一工具,但给它不熟悉的那个会消耗额外的推理 token,并产生更多错误。因此在我们的 harness 中,我们为每个模型配置其训练时使用的工具格式。
这种定制极为深入,包括针对不同提供商乃至不同模型版本的自定义提示词。OpenAI 的模型在指令遵循上往往更字面、更精确,而 Claude 则更直觉化,对不精确的指令也有更强的容错性。
当我们在新模型发布前提前获得内测资格时,我们会从最接近的现有模型的 harness 出发开始迭代。我们运行离线评测,找出模型感到困惑的地方,让团队成员实际使用并反馈问题,然后针对性地调整 harness。如此往复,直到模型与 harness 的组合达到我们认为可以发布的水准。
调优过程很大程度上是将 harness 定制到新模型的优势上,但有时我们也会遇到真正的模型怪癖,并借助 harness 加以缓解。例如,我们曾观察到一个模型出现我们称之为"上下文焦虑"的现象:随着上下文窗口填满,它开始拒绝工作,以任务看起来太大为由不断搪塞。我们通过提示词调整,成功减弱了这一行为。
支持对话中途切换模型
设计 harness 以支持用户在对话中途切换模型,是一项尤为棘手的挑战,因为不同模型有不同的行为、提示词和工具形态。
当用户切换模型时,Cursor 会自动切换到对应的 harness,包含该模型定制的提示词和工具集。然而,模型仍需将这些工具应用于由另一个模型产生的对话历史——而这段历史不在它的训练分布之内。
为此,我们添加了自定义指令,告知模型它正在对话中途接替另一个模型。这些指令还会引导它避免调用出现在对话历史中但不属于其自身工具集的工具。

第二个挑战是:缓存与提供商和模型绑定,切换模型意味着缓存失效,导致第一轮对话更慢、成本更高。我们曾尝试通过在切换时摘要对话来缓解这一问题——为模型提供一份简洁的摘要,降低缓存惩罚。但如果用户正深陷一个复杂任务,摘要可能会丢失重要细节。我们通常建议,除非有充分理由,一次对话中尽量坚持使用同一个模型。
另一种绕开对话中途切换模型挑战的方式,是改用子 agent——它从全新的上下文窗口开始。我们最近在 harness 中新增了让用户直接指定以特定模型运行子 agent 的功能。
Harness 与软件开发的未来
AI 辅助软件工程的未来,属于多智能体。系统不会再将每个子任务都路由给单一的 agent,而是学会将任务分发给专业化的 agent 和子 agent:一个负责规划,一个负责快速编辑,一个负责调试,各司其职,各展所长。
让这一切运转良好,本质上是一个 harness 挑战。系统需要知道该调度哪个 agent、如何为该 agent 的优势量身定制任务框架,以及如何将结果拼接成连贯的工作流。协调这种复杂编排的能力,将存在于 harness 之中,而非任何单一 agent。这意味着,harness 工程一直以来都对 agent 的成功至关重要——而在未来,它只会变得更加关键。