Shopify:如何利用autoresearch模式把持续实验做成工程自治引擎
一个从 CI 变慢出发、把 AI 研究循环改造成工程自治引擎的完整案例故事。
一个很普通、但很值钱的工程问题
有些工程问题不是“写不出代码”,而是“等得太久”。
Shopify 的 Polaris 团队就遇到过这种情况:做一个很小的改动,CI 经常会跑出随机的视觉回归失败。你得先等大约 30 分钟,才能知道这次改动到底有没有把系统弄坏;如果失败了,还得再来一轮。对工程师来说,这不是单纯的慢,而是反馈闭环太长,长到足以把人拖垮。
这类问题最麻烦的地方在于,它们通常都满足三个条件:
- 结果是可测的:比如构建时间、测试时间、渲染时间、失败率、分配开销。
- 优化是有价值的:快 10%、20%、甚至 65%,都能真实改变团队效率。
- 但人类不愿意长期做:它看起来像 toil,没有“新功能”那么体面,也没有“架构重写”那么有戏剧性。
真正难的不是“知道它该优化”,而是“谁来持续地盯着它优化”。
Autoresearch 是什么,pi-autoresearch 又是什么
先把概念讲清楚。
Autoresearch 最初是 Karpathy 提出来的一种研究循环:让 AI 像研究员一样工作——提出假设、做实验、观察结果、继续迭代。它原本是拿来做模型训练的。
pi-autoresearch 则是 Shopify 把这个思路工程化之后做出来的开源实现。你可以把它理解成:
- Autoresearch = 方法论 / 循环框架
- Pi = 承载这个循环的 agent harness
- pi-autoresearch = 让 Pi 以自治循环方式持续优化指标的扩展
所以,pi-autoresearch 不是 Autoresearch 的同义词,而是它在 Shopify 场景下的可执行版本。
这次 Shopify 做的,不是一个 agent demo,而是一种新工作方式
Shopify 的做法很有意思:他们没有把 AI agent 当成“会聊天的代码生成器”,而是把它变成了一个持续实验的执行者。
你可以把这件事理解成一句话:
让 agent 在一个明确、可测的指标上反复试验,系统只保留真正更好的变化。
这和很多人想象中的 AI 编程不一样。
不是:
- “帮我写个优化方案”
- “给我一个一次性的补丁”
- “把这个项目改快一点”
而是:
- 先定义一个指标
- 让 agent 反复提出假设
- 运行实验
- 测量结果
- 把更好的改动保留下来
- 把失败或变慢的改动丢掉
- 然后继续下一轮
这套流程的本质是:把工程优化从一次性任务,变成一个可以长期运行的自治循环。
图怎么读
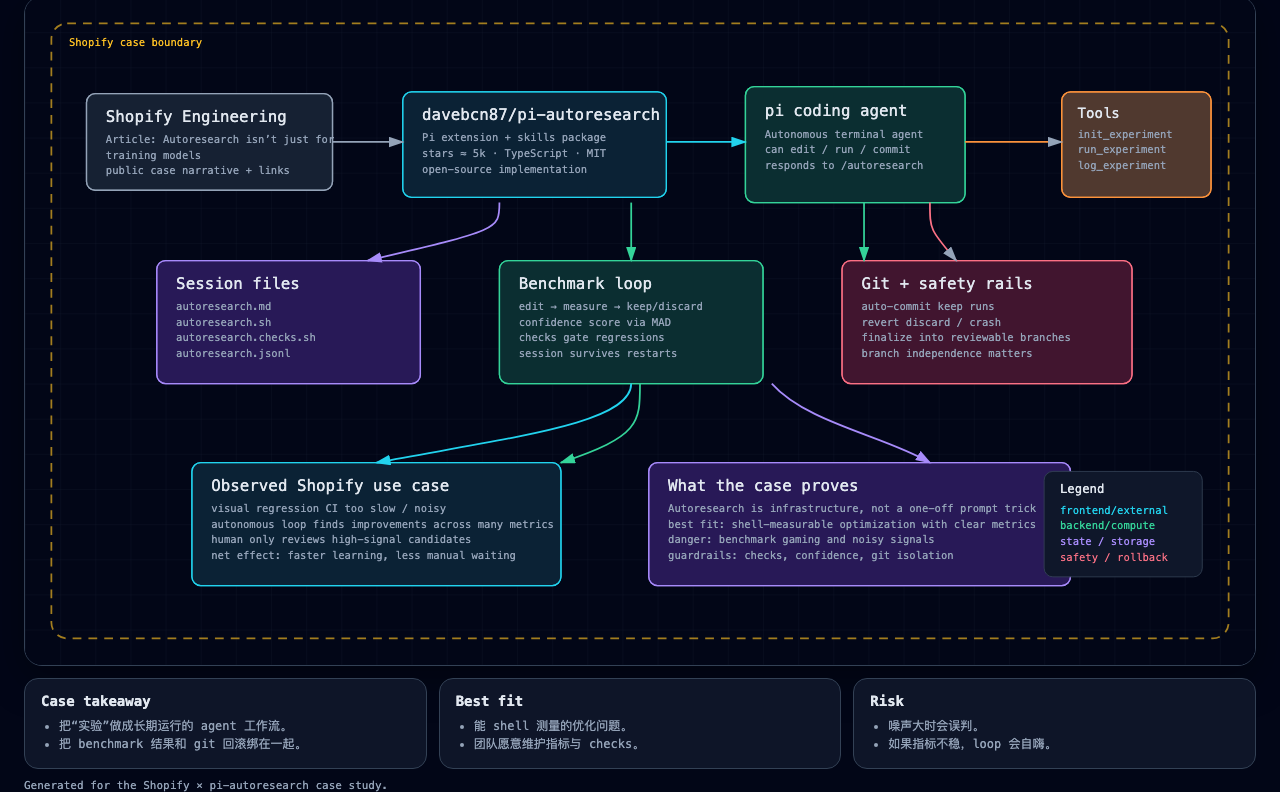
这张图不是装饰,它表达的是整个工作流:
- 左边:真实工程问题,慢 CI、随机失败、重复验证
- 中间:Pi agent + pi-autoresearch 扩展,负责执行和试验
- 右边:自治循环,负责测量、比较、保留、丢弃、继续
autoresearch.md:当前实验的工作记忆autoresearch.jsonl:可追溯的实验历史run_experiment/log_experiment:控制实验开始、结束、记录的核心动作
换句话说,这套系统不是“一个聪明的 prompt”,而是一个可以长期运转的工程实验引擎。
故事是怎么开始的
作者最初面对的问题很朴素:如何把 Polaris 的构建时间降下来。
他先试过更直接的方式:让 agent 一次性去“优化 build time”。但这条路效果不好,原因也很直白:
- 目标太大
- 没有清晰的反馈闭环
- agent 会一股脑乱试
- 很容易得到一个不能 build 的方案
于是他换了一种方式:把优化拆成一个持续循环。
这个循环具体怎么跑
第一版其实非常简单。
1)先选一个指标
比如 build time。
这个例子里,baseline 是 19.1 秒。
2)让 agent 提出假设
它不是直接改代码,而是先说:
- 哪个环节可能是瓶颈?
- 哪部分工作可能重复了?
- 哪些步骤其实没必要?
- 有没有更短的路径?
然后再去验证。
3)每轮实验只分三种结果
- 比 baseline 更快:保留
- 更慢:丢弃
- 直接崩了:丢弃
这一步非常关键。它逼着系统只接受真正有价值的改动,而不是“看起来很聪明”的改动。
4)继续循环
只要指标还可以继续优化,系统就继续跑。
人类工程师做不到这一点,因为人会累,会切任务,会被别的需求拉走,会觉得“这个优化先放一放”。
agent 不会。
它可以不停试,不停测,不停筛选。
这就是 Autoresearch 真正的价值:不是一次性解决问题,而是持续把问题往下压。
一段实际过程,应该怎么理解
读者最想看的,其实不是抽象概念,而是“它到底怎么把 30 分钟变短”的过程。
Shopify 文章里,真正有价值的不是一个神奇的 AI 魔法,而是 agent 持续找到了几个重复劳动:
关键实验 1:VRT 构建里有重复流水线
原来的流程先跑了完整的组件流水线,包括:
- IIFE bundle
- type declarations
- 其他前置步骤
但问题是,后面的 Storybook 会再从源码重新编译一遍。
这意味着前面那部分有一截是重复劳动。
agent 试出来的关键改动,不是“换一个更酷的框架”,而是把这段重复工作砍掉。
关键实验 2:TypeScript transform 处理了太多文件
另一个发现是:
- TypeScript transform 处理了 580 个组件文件
- 但真正需要它的只有 105 个
这类问题人类很容易忽略,因为它们太细、太琐碎、太不像“项目主线”。
但 agent 可以持续试,直到把这些隐藏的浪费揪出来。
关键结果:累计起来,构建时间下降了 65%
所以,“65% 的提升”不是来自一句空洞的“accumulated incremental improvements”,而是来自一连串能被验证的局部优化:
- 去掉重复步骤
- 缩小不必要的处理范围
- 过滤掉不能 build 的方案
- 只保留真正跑得更快的变更
这才是案例的价值:过程是可追踪的,收益是由一个个小实验叠出来的。
三个核心机制,给你一个更直观的样子
下面这几段不是原文逐字内容,而是根据它的工作方式整理出来的“可读示意”。目的只有一个:让你看见它怎么运转。
autoresearch.md 示意
# Goal
Reduce Polaris build time
# Baseline
19.1s
# Current hypothesis
Skip redundant VRT pipeline before Storybook recompiles from source
# Rule
Only keep changes faster than baseline这个文件的作用不是写作文,而是让 session 可以接着跑。换一个 agent 来,也知道现在在优化什么、基线是多少、当前假设是什么。
METRIC 输出示意
METRIC build_time_seconds=12.4
METRIC status=pass这个输出的意义很简单:把实验结果变成机器可判断的数字。只要数字更好,就保留;否则丢弃。
一轮实验的判断示意
Hypothesis: remove redundant precompile step
Result: build_time_seconds 19.1 -> 12.4
Decision: keep你会发现,这个系统最重要的不是“能不能写代码”,而是它把“实验—判断—继续”这件事做成了闭环。
Pi 在这里扮演什么角色
Pi 不是背景板。
它是那个把 Autoresearch 真正跑起来的 agent harness。可以把它理解成:
- Agent 的执行环境
- 实验的调度器
- 记录和回放的载体
Shopify 的做法不是让模型在聊天框里“思考一下”,而是把它放进一个真的实验工作台里。
这也是为什么它能从一个内部尝试,变成一个可以复用、可以扩展、可以开源的工具。
这不是一个人的 hack,而是可以被团队接住的系统
作者把这个扩展发到内部 Slack 后,Tobi 也参与进来,而且不是随便看热闹,而是直接帮它产品化:
- 多指标支持
- 每轮统一执行脚本
- 自动 commit
- 更好的扩展封装
- 更稳定的实验流程
这说明一件事:
它不是一个人的小聪明,而是一种团队能接住、并继续放大的工程模式。
为什么这种方式比“一次性让 agent 优化”更强
如果只是直接对 agent 说“优化 build time”,它很容易:
- 方向太散
- 试错太粗暴
- 产出一个不能 build 的方案
- 或者只得到一个局部最优但不稳定的结果
但一旦把它放进自治循环,情况就不同了:
- 目标更窄
- 指标更清楚
- 反馈更快
- 实验更密集
- 失败成本更低
- 长期收益更高
这时候,agent 不是在“写一个答案”,而是在“寻找一条更优路径”。
这套模式适合谁,边界又在哪里
适合的团队
最适合:
- 做构建、测试、渲染、性能优化的工程团队
- 有明确 metric、且能自动化测量的人
- 想让 agent 持续做实验,而不是只写一次代码的人
- 有能力设置正确性护栏、review 结果、接住自动化变更的团队
不适合的场景
不适合:
- 目标很模糊、无法量化的任务
- 没有稳定 benchmark 的场景
- 结果无法自动验证的任务
- 需要高度主观判断的产品决策
国内有没有类似实践?
有方向相近的实践,但多数团队还停留在:
- 自动化回归
- 性能监控
- CI 优化脚本
- LLM 辅助排查
真正稀缺的是把这些能力串成一个持续实验闭环: 不是“报警—人工看—人工改”,而是“试验—测量—保留—继续”。
Shopify 的新意就在这里:它把 agent 从“帮你写点东西”,推进到了“帮你持续做优化”。
一句话总结
Shopify 这件事最厉害的地方,不是“让 AI 帮忙写了点代码”,而是他们把 Autoresearch 变成了一个工程自治引擎:让 agent 在可测指标上持续实验,把人类最不想做、但又最值钱的优化工作自动化。
参考
- Shopify Engineering 原文:https://shopify.engineering/autoresearch?a=1
- 开源项目:https://github.com/davebcn87/pi-autoresearch