antirez 的选择:当推理引擎只为一个模型而生
Redis 创始人 antirez 用纯 C 为 DeepSeek V4 Flash 写了一个专用推理引擎 DS4,抛弃了 llama.cpp 的通用抽象层。这个项目引出一个值得认真想清楚的问题:通用推理框架的代价,究竟是多少?
antirez 的选择:当推理引擎只为一个模型而生
Redis 创始人 antirez 上周在 GitHub 上传了一个项目:DS4。
这是一个纯 C 写成的 DeepSeek V4 Flash 专用推理引擎。它不支持任何其他模型,不读取任意 GGUF 文件,也不试图跑在通用的 GPU 生态上。它只做一件事——在 Mac 的 M 系列芯片(和 CUDA GPU)上,把 DeepSeek V4 Flash 这一个模型跑到极致。
HN 上 490 票,152 条评论。不是因为人们都认为这是对的选择,而是因为这个项目清晰地摆出了一道题:通用推理框架(llama.cpp/GGUF)的代价,究竟是多少?
DS4 做了什么
先把技术事实摆清楚,再谈判断。
DS4 是 DeepSeek V4 Flash 的专用 Metal 和 CUDA graph executor,集成了 prompt rendering、KV state 管理和 OpenAI/Anthropic 兼容的 server API。它有几个和 llama.cpp 路线截然不同的设计:
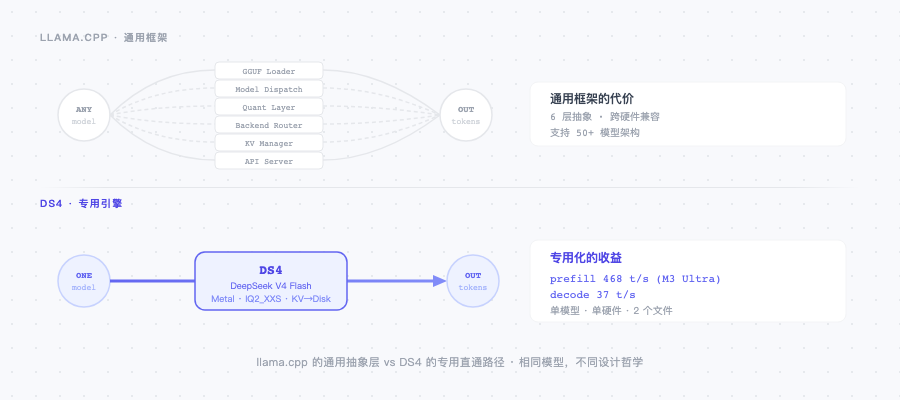
1. 不加载通用 GGUF,只认特定的张量布局和量化组合。 llama.cpp 的核心价值是:写一套代码,跑所有 GGUF 格式的模型,支持所有主流 GPU 家族。DS4 抛弃了这个目标。它用的量化格式仍然借鉴自 llama.cpp(IQ2_XXS / Q2_K),但 GGUF loader 的抽象层完全去掉了。antirez 说得直接:任意 GGUF 文件不会有 DS4 所需的张量布局、量化混合和 metadata,你拿别的文件来是跑不了的。
2. KV cache 当作磁盘一等公民。 这是 DS4 里最有意思的架构决定。通常推理引擎把 KV cache 当做 RAM 中的临时状态。DS4 把它持久化到磁盘,用 SHA1 命名 checkpoint 文件——意味着你可以跨重启、跨 session 恢复之前的推理状态。这背后的假设是:现代 SSD 的速度已经快到让这个方案可行了。
3. 代码量极小。 antirez 自己说:整个东西就几个文件,逻辑清晰,容易推导。通用框架为了支持数十种模型架构、数十种量化格式、数十种硬件,代码量和抽象层必然膨胀。DS4 的窄范围让它可以保持小。
数字说明了什么
M3 Max(128GB,Q2 量化):
- 短 prompt:prefill 58.52 t/s,generation 26.68 t/s
- 长 prompt(11.7k tokens):prefill 250 t/s,generation 21.47 t/s
M3 Ultra(512GB,Q2 量化):
- 短 prompt:prefill 84.43 t/s,generation 36.86 t/s
- 长 prompt:prefill 468 t/s,generation 27.39 t/s
这些数字本身并不算震撼——llama.cpp 在相同硬件上跑 DeepSeek V4 Flash 也有不错的表现。DS4 目前没有提供和 llama.cpp 的直接对比。
但 HN 评论里有一个数据点值得关注:有人优化了 Qwen3.6 MoE 的推理后,prefill 提升 20%,decode 提升 50%。这个幅度不是调参能得到的,是去掉通用抽象层、针对具体模型+硬件组合做专项优化才能得到的。
DeepSeek 自己也证明了这件事:他们的自定义 PTX 代码在 H800 GPU 上跑赢了标准 CUDA 实现。这是从模型发布方的角度验证了同一个结论:针对单一硬件实现的专用代码,性能上确实有空间。
反方论点也是对的
HN 讨论里有人提出了同样有道理的反驳:
"更好的时间利用方式是把这些优化 upstream 到通用框架,而不是造专门的 model+GPU runner。"
这个论点站得住。llama.cpp 已经在 Metal 路径上做了大量针对 Apple Silicon 的优化。专用引擎每多一个,生态就多一份碎片化。优化成果也无法被其他模型的用户复用。
还有一个更现实的问题:模型在变。DeepSeek V4 Flash 今天是最值得优化的目标,六个月后呢?专用引擎的生命周期和它所绑定的模型一起结束。llama.cpp 跑完了无数已经被遗忘的模型,还在跑最新的。
专用化什么时候值得
从这件事里我能提炼出一个判断框架,给自己用的。
场景一:模型已经稳定,你打算长期跑它。 如果你的生产环境锁定了某一个模型版本,不打算跟随每次更新,专用化的投入才有回报。这在学术研究场景、特定企业部署场景里是真实存在的。
场景二:硬件已经明确,性能是瓶颈。 你用的是 M3 Ultra、H800、或者某个特定的推理加速器,而且推理延迟直接影响用户体验或成本。这时候通用框架的跨硬件抽象是真正的负担。
场景三:你需要的是可推导的系统,而不是功能最全的系统。 这是 antirez 自己强调的理由。"几个文件,容易推导"不是工程上的弱点,是某类用户的核心诉求——能读懂、能改、能 debug,不依赖黑箱。
如果这三个条件你一个都不满足,llama.cpp 是更合理的选择。它的通用性不是缺点,是为不确定性付的保险费。
软件工程里一个反复出现的模式
SQLite 和通用关系型数据库的关系类似。SQLite 的设计假设是:你只需要一个文件,不需要并发写,不需要网络协议,不需要事务复制。在这个范围内,它比任何通用数据库都更快、更简单、更可靠。走出这个范围,它就不合适了。
nginx 和 Apache 也是。nginx 赌定了"高并发静态文件服务"这一个场景,Apache 要支持所有场景。在那个特定场景里,nginx 赢了。
专用化能赢的条件是一致的:明确的场景边界 + 场景内足够大的需求量。
DS4 现在能不能赢,取决于这两个条件里"场景边界"有多稳定——DeepSeek V4 Flash 作为一个锚点,能撑多久。
我的判断
antirez 做这件事的意义,不主要在于 DS4 会不会成为主流推理引擎——它大概不会。
意义在于:它提供了一个干净的对照实验,告诉我们通用框架的抽象层到底在哪些地方是有代价的。MoE 模型的 expert routing、Apple Silicon 的 Metal 路径、KV cache 的磁盘持久化——这些优化在通用框架里要么做得不彻底,要么根本没做。DS4 把这些可能性摆出来了。
接下来的问题是:哪些优化能被反向移植到 llama.cpp?KV cache 作为磁盘一等公民,这个想法是通用的,不只对 DeepSeek V4 Flash 有价值。如果这个方向被社区验证,它会进主线。
对正在搭建本地 AI 推理栈的人来说,DS4 现在不是你要用的工具,但它是你应该读的代码——如果你想真正理解推理优化的边界在哪里。