OpenAI 用上 Google 水印,AI 内容溯源正在变成行业基础设施
同一天,Google I/O 全产品线强推 SynthID 水印,OpenAI 正式采纳同一技术。C2PA 元数据 + 像素级水印的双层溯源正在成为行业标配,而这场博弈的背后是 AI 时代「可信内容」的定义权之争。
May 19 这一天,AI 行业发生了两件看起来无关的事。
Google I/O 上,皮查伊发布了 Gemini Omni。一个能从文本、图片、音频生成视频的世界模型。它在 Gemini 应用、YouTube Shorts、Flow 创意工作室里同时上线,每段生成内容都带一个不可见的水印,叫 SynthID。
同一天,OpenAI 发了一篇博客,标题叫《Advancing content provenance》。内容很简单:OpenAI 正式采纳 Google DeepMind 的 SynthID 技术,为 ChatGPT、Codex 和 OpenAI API 生成的所有图像嵌入这个水印。同时,OpenAI 成为 C2PA 认证生成产品,并推出面向公众的验证工具。
竞争对手在同一天各自宣布了同一件事。这件事关乎的,是 AI 时代一个极其基础又极其棘手的问题:你怎么知道你看到的东西,是被 AI 生成的?
更准确地说,当 C2PA 元数据可以被截图剥离、当一张图在微信和 Telegram 之间转了五次之后,你拿什么证明它来自哪里?
两层溯源
OpenAI 的新方案是一个双层结构。
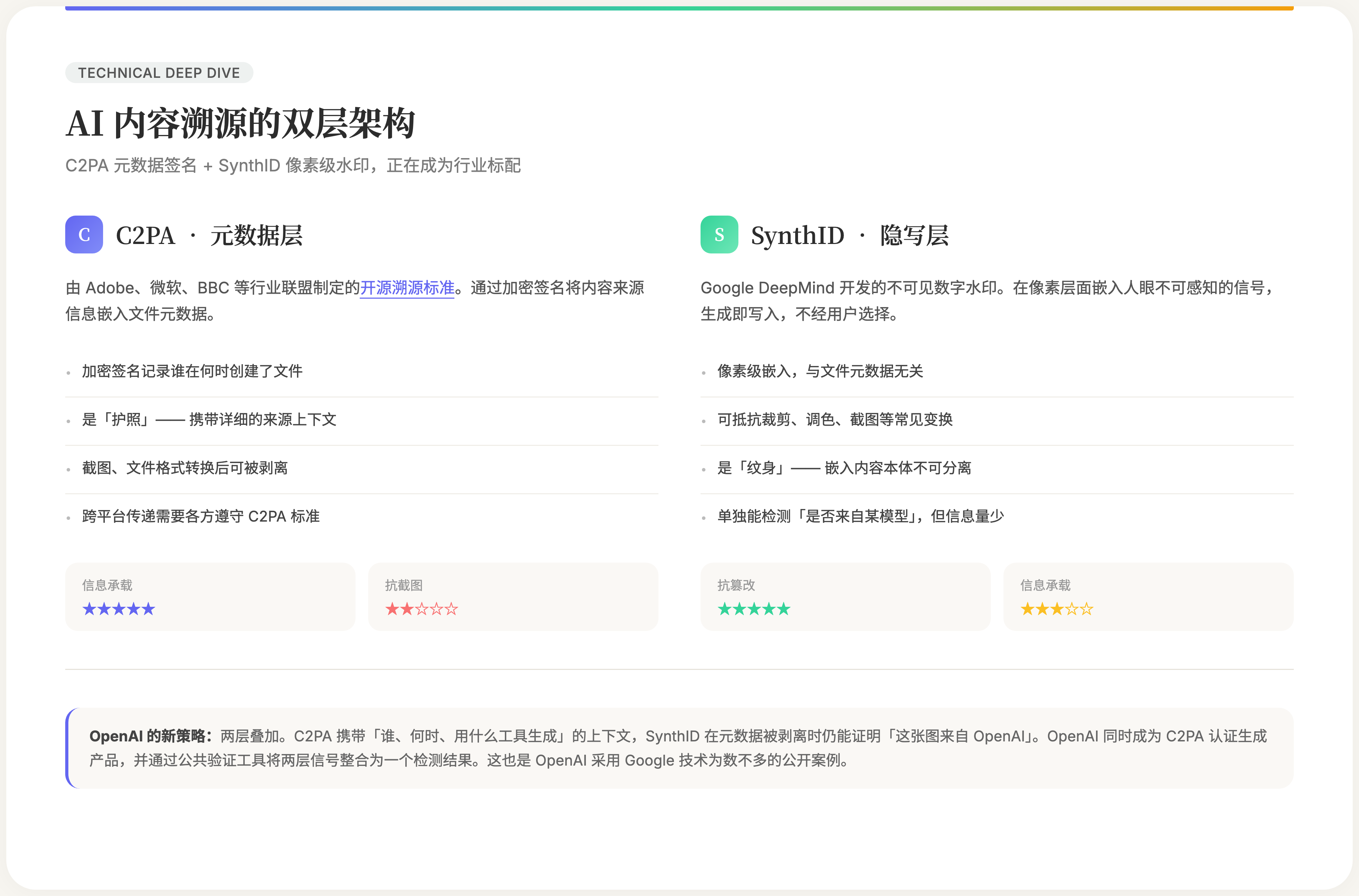
第一层是 C2PA。Coalition for Content Provenance and Authenticity,由 Adobe、微软、BBC 等成立的行业联盟。C2PA 的思路是用加密签名把内容来源信息写进文件元数据:谁在什么时间用什么工具创建了这份内容,签名是否有效。OpenAI 从 2024 年就开始做这个,DALL·E 3、Sora 都加了 C2PA 标签。最近 OpenAI 正式成为 C2PA 认证生成产品,意味着平台可以信任并传递 OpenAI 附带的溯源信息。
但 C2PA 有个天然弱点。元数据可以被剥离。上传下载、格式转换、截图、微信压缩,这些操作都可能把 C2PA 标签洗掉。一张图在跨平台传播一圈之后,元数据往往已经不在了。
这就是 SynthID 补上的那层。
SynthID 不是元数据。它是 Google DeepMind 开发的一个不可见水印技术,直接在像素层面嵌入信号。人眼完全感知不到它的存在,但 SynthID 的检测工具可以判断这张图是否被标记过。更重要的是,它能抵抗裁剪、调色、压缩、帧率变化等常见操作。截图?它还在。
OpenAI 对这两层的描述很精确:C2PA 是护照,携带详细的来源上下文;SynthID 是纹身,嵌入内容本体,不可分离。护照可能丢,但纹身跟着人走。
OpenAI 的公共验证工具会将两层信号整合在一起检测。如果只检测到 SynthID 水印但没有 C2PA 元数据,工具会告诉你「检测到来自 OpenAI 的水印信号」,但不会做绝对结论——因为溯源信号在某些情况下可能被剥离。
有意思的是,这个策略的核心技术来自 Google。
同一个夜晚
把时间线拉回到同一天。
Google I/O 上,SynthID 不只是图片水印了。Gemini Omni 生成的视频同样嵌入 SynthID。所有视频带水印。Google 的 AI 产品全线强制推水印。
OpenAI 这边,选择的是采纳。不是合作研发,不是自研替代方案,是直接在产品线里接入对手的技术。坦白讲,OpenAI 和 Google 在 AI 领域的竞争已经到了白热化程度——诉讼、模型竞赛、定价战——但在这个议题上,双方选择了同一条路。
这个信号比水印本身更值得关注。

AI 内容溯源正在从「可选项」变成「必选项」。不是某个公司的差异化策略,而是行业基础设施。就像 HTTPS 一样,早期是优秀实践,后来成为标准,最终成为强制要求。2024 年美国总统大选期间,AI 生成的虚假竞选广告曾经引发巨大争议,此后 C2PA 的推进速度明显加快。到 2026 年 5 月,两家最大的 AI 公司同时把溯源基础设施提升到了全产品线级别。
从「各自为政」到「互操作性」
这个趋势的下一个阶段,应该是跨平台验证。
目前 OpenAI 的验证工具只限于检测自家生成的内容。Google 的 SynthID Detector 目前也只面向记者和媒体专业人士内测。但两边的方向是一致的:当水印成为全行业标准,你需要的不只是检测自己的内容,而是能验证一切内容。
OpenAI 在博客里也提到了这个方向:「在未来几个月,我们计划支持跨行业努力,使验证可以在多个平台上进行。」翻译一下就是:SynthID 检测能力应该开放给所有平台,不只限于 OpenAI。
这也意味着一个更深层的问题正在浮出水面:AI 生成内容的溯源,最终会走向一个统一标准,还是多个互相不兼容的标准?C2PA 是开放的行业标准,SynthID 是 Google 的技术。如果 SynthID 成为事实标准,Google 就拥有了溯源基础设施的核心控制权。如果 C2PA 标准进一步扩展,行业可能走向更加去中心化的方向。
这场博弈的结果,将决定 AI 时代「可信内容」的定义权归属。
AI 生成已经抵达一个临界点
ChatGPT 图像生成功能每周使用量已经突破 15 亿次。Google 的 Nano Banana 模型累计生成超过 500 亿张图片。这些数字意味着,现在互联网上每天新增的内容中,AI 生成的比例正在快速上升。没有溯源机制,这些内容将以不可分辨的方式融入信息流。
溯源本身并不是一个完美方案。没有检测方法是万无一失的——OpenAI 自己也说,当且仅当没有任何水印可检测时,工具不会对内容来源做任何结论。但溯源的价值不在于绝对可靠,而在于增加作恶成本。当每一张 AI 生成的图片都带着一个难以移除的标记,用 AI 制造虚假信息就不再是零成本的事情了。
一个值得关注的细节:OpenAI 没有对语音生成做 SynthID。Voice Engine 用的是音频水印,但不是 SynthID。Google 的 SynthID 目前支持图片、视频、音频,而 OpenAI 只做了一部分。这既是技术路线差异,也可能反映了双方在溯源能力上的差距。
更深层的问题是,在接下来的视频和 3D 内容爆发期,同步部署溯源基础设施会变得更困难。Gemini Omni 可以在生成视频的每一帧嵌入 SynthID,这样的原生集成远比事后加上水印要可靠。这一步,Google 已经走在了前面。