db9.ai: Postgres for Agents
黄东旭(PingCAP CTO)的最新作品 db9.ai 上了 HN 首页。这是一个给 AI Agent 用的 serverless PostgreSQL 数据库,基于 TiKV,内置向量搜索、文件系统 fs9、cron、HTTP 调用。
黄东旭又在折腾了。
这位 PingCAP CTO、TiDB 联合创始人,2025 年闭关几个月后,掏出了一个叫 db9.ai 的东西。官网第一行写得清楚:
「Create, manage, and query serverless PostgreSQL databases from your terminal.」
不是笔产品,不是笔记工具,是一个 Postgres for Agents——给 AI Agent 用的 serverless 数据库。
一个 CTO 的空窗期产物
黄东旭,PingCAP 联合创始人兼 CTO,TiDB 的核心作者之一。2025 年上半年,他在 PingCAP 的角色逐渐淡出后,进入了一段「闭关期」。
他在原文里写得很坦诚——「燃烧了几百亿 token(都是 Opus 4.6 + GPT 5.2 😭),加上独立发现了 Harness Engineering」,最终得到了 db9.ai 这个产物。
这个背景很重要。这不是一个经过董事会批准的创业项目,而是一个顶级技术人在 空窗期的自然产出。他对自己要解决的问题有极端清晰的判断:AI Agent 正在成为新的软件交互主体,但它们的数据存储层仍然是分裂的。
Agent 需要两个核心接口:
- SQL —— 结构化数据操作,PostgreSQL 协议是事实标准
- 文件系统 —— 非结构化数据管理,ls / cp / grep / glob 是 Agent 最自然的心智模型
这两个接口在过去一直是分裂的。db9.ai 的野心就是把它们融合在一起。
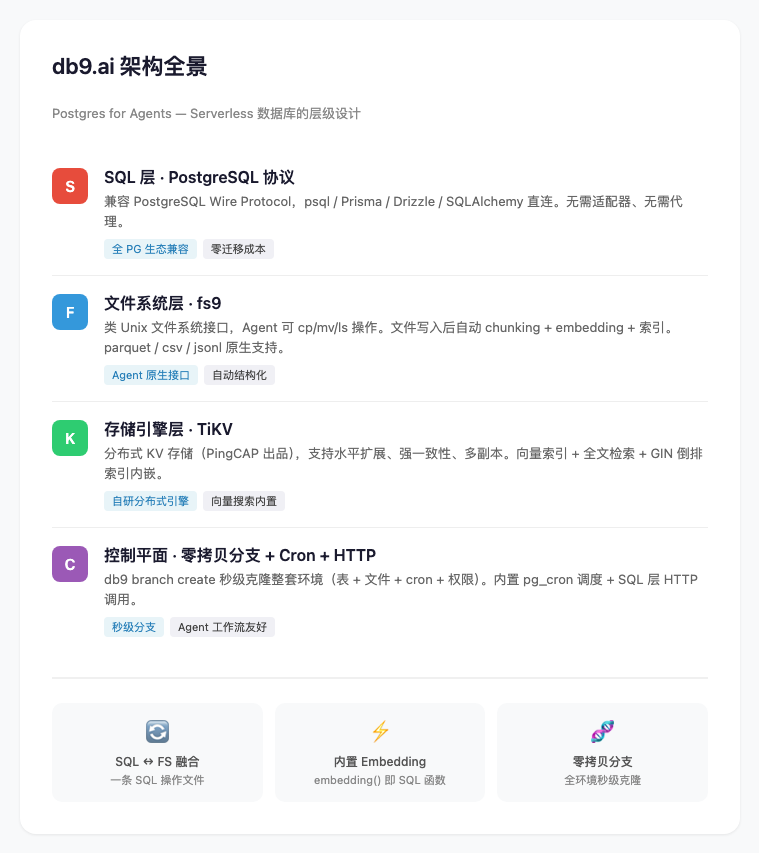
架构拆解:不是又一个 PG 封装
db9.ai 的底层是 TiKV —— PingCAP 的分布式 KV 存储,黄东旭本人的作品。这意味着它从内核上就是一个分布式存储,而不是给单机 PostgreSQL 套了一层皮。
在这个基础上,db9.ai 做了四件核心的事情:
1. PostgreSQL 协议兼容
任何连接 PostgreSQL 的工具——psql、Prisma、Drizzle、SQLAlchemy,直接连。没有适配器,没有中间层。
这对 Agent 来说意味着什么:Agent 生态里最成熟的工具链全部可以直接使用,不需要任何学习成本。
2. 内置向量搜索和 Embedding
Embedding 不是外部服务,是 SQL 函数:
-- 相似度搜索,Embedding 内置
SELECT title, content FROM docs
ORDER BY vec <-> embedding('deploy to production')
LIMIT 5;
-- 生成 Embedding
UPDATE docs SET vec = embedding(content) WHERE vec IS NULL;不需要部署向量数据库,不需要配置 Embedding Pipeline,不需要处理数据同步。所有操作在一条 SQL 里完成。
对 Agent 来说这是个巨大的心智简化——它不需要区分「结构化的存在数据库中」和「非结构化的存在向量数据库中」,一切都是 db9 里的表。
3. 文件系统 fs9
这是 db9.ai 最有想象力的部分。
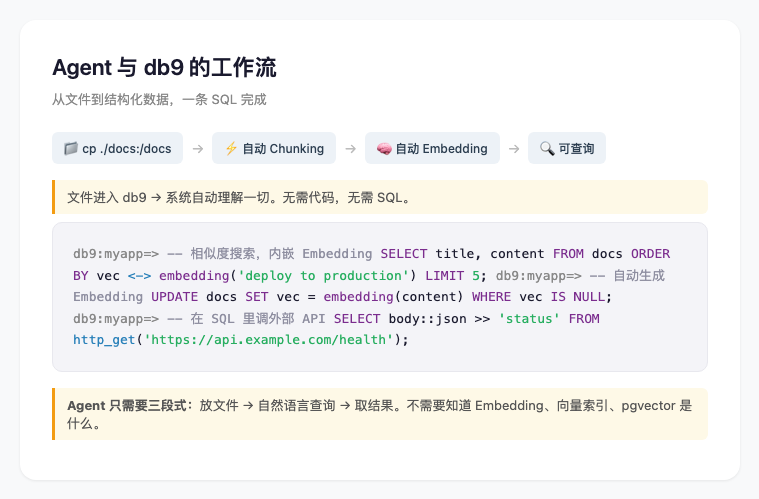
Agent 不需要学 SQL 来使用 db9。最简单的入口是:
cp -r ./docs:/docs文件复制进去后,db9.ai 自动做 chunking、embedding、索引构建。后续可以直接用自然语言查询。
这里的内核基础来自黄东旭上一个开源项目 agfs(https://github.com/c4pt0r/agfs),一个给 Agent 用的文件系统。agfs 被字节跳动的火山引擎用到了 OpenViking 上作为存储组件,现在它的设计思想被融合到了 db9.ai 之中。
更有意思的组合是 SQL + 文件系统的融合:Agent 3 秒钟生成了一条 SQL,把一个 CSV 文件当作表来处理,去重后写入,1 shot 成功。而且可以变成一个 pg/PLSQL 存储过程,对文件系统的变更进行 trigger 后自动执行。
文件进来 → 自动触发 SQL 处理 → 结构化存入 → 可查询。一条完整的非结构化到结构化的自动化链路。
4. 零拷贝分支 + 内置 Cron + HTTP
$ db9 branch create myapp --name staging
Branch 'staging' created from database myapp.
Name staging
State ready
✓ Tables & rows
✓ Files & uploads
✓ Cron jobs
✓ User permissions
✓ Extensions分支是全量的——不只是表和行,还包括文件、cron 配置、权限。这对 Agent 工作流尤其重要:每个 Agent 任务可以有一个独立的数据库分支,用完即弃。
内置的 pg_cron 和 HTTP 调用让 Agent 可以在 SQL 层完成定时任务和外部 API 调用,不需要额外的调度系统。
db9.ai vs 传统方案
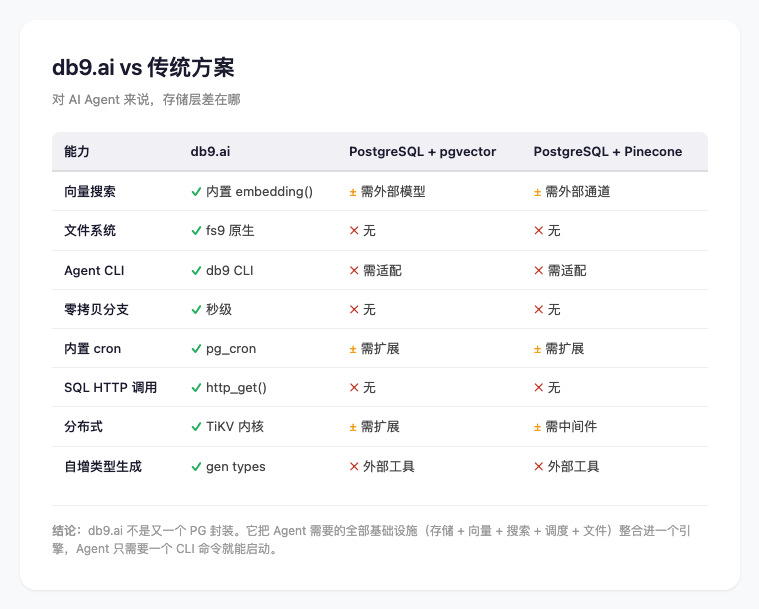
为什么这件事有意思
db9.ai 的选择不是技术上的炫技,而是对 计算范式的判断。
黄东旭在原文里说:「去年下半年,我开始做第一个开源的 agent 文件系统尝试,叫 agfs。」那篇引言文章(https://aivanguardian.com/p/ai-agents-need-new-infrastructure)提到,Agent 需要的新型基础设施,存储是关键一环。
这个判断的底层逻辑是:当交互主体从人变成 Agent,存储层的接口需要被重新定义。
人的接口是 UI、Dashboard、REST API。Agent 的接口是 SQL、文件系统、CLI。这两套接口的心智模型完全不同。db9.ai 选择同时支持两者,但以 Agent 的心智模型为主。
这不是一个小众选择。如果你看 db9.ai 首页的合作列表——Claude Code、OpenAI Codex、Cursor、Cline、VS Code、OpenCode、OpenClaw、Vercel——就明白了。所有主流 Agent 和开发工具都在尝试接入。
和黄东旭之前的选择放在一起看
TiDB 解决了「MySQL 水平扩展」的问题。db9.ai 在解决「Agent 怎么用数据库」的问题。
两件事的规模差了一个数量级,但思路线是一致的:找到被忽视的接口层,然后把它做对。
十年前,分布式数据库的接口是 MySQL 协议,但 MySQL 的分布式扩展是一个没有得到解决的问题。现在,Agent 的数据接口是 PostgreSQL 协议 + 文件系统,但这两者的融合是一个没有得到解决的问题。
黄东旭不过是又一次回到了自己最擅长的地方。
尾巴
db9.ai 还非常早期。产品在快速迭代,文档在补全,生态在构建。现在下结论说它会成为 Agent 时代的存储标准,还为时过早。
但这件事本身就值得关注——不是因为产品本身有多完美,而是因为这代表了一种范式判断:下一个计算时代的基础设施,正在被最了解分布式系统的那批人,从头构建。
Postgres but for agents.