200ms 节拍:拆解 Thinking Machines「交互模型」的架构假设
前 OpenAI CTO Mira Murati 创立的 Thinking Machines Lab 发布了一种全新的「交互模型」架构——原生多模态、全双工、200ms 节拍维持在场感。这不是又一个 Agent 框架,而是对「人机该怎样协作」这件事的根本性重写。
一个被默认假设锁死的交互范式
你跟 AI 对话的方式,本质上还停留在 2022 年。
你说一句,它答一段。你等它说完,再输入下一句。每次交互都是一个回合——你发起,它响应,然后等待下一轮发起。
这种「回合制」(turn-based)范式几乎是今天所有 AI 产品的默认交互模型。ChatGPT 是,Claude 是,Gemini 也是。它简单、可预测、容易工程化。但它有一个根本性的缺陷:
它假设人类和机器不会同时说话。
人类协作从来不是这样的。开会时有人插话,有人点头,有人在对方说完之前就接上了思路。真正的协作是全双工(full-duplex)的——信息流双向同时传输,而不是轮到你才开口。
这就是 Thinking Machines Lab 刚刚发布的东西试图解决的问题。他们称之为**「交互模型」**(Interaction Model),一种原生多模态、全双工、200 毫秒节拍的人机协作架构。
这不是又一个 Agent 框架的变体。这是对交互底层假设的一次重构。
先搞清楚他们在做什么
Thinking Machines Lab 是由 Mira Murati(前 OpenAI CTO)在 2025 年 2 月创立的公司。她带走了 OpenAI 多位核心成员,包括前研究副总裁 Barrett Zoph(担任 CTO)和联合创始人 John Schulman(担任首席科学家),在创纪录的 20 亿美元种子轮融资后,估值一路涨到 1.4 万亿美元。
公司此前的公开产品线包括:
- Tinker(2025.10)—— 一个让开发者微调开源模型的 API 平台
- NVIDIA 千兆瓦级算力合作(2026.3)
- Connectionism(尚未正式发布)—— 据推测就是今天报道的「交互模型」产品线
今天的信息来自歸藏对 Thinking Machines 产品演示的报道。核心内容非常清晰:
Thinking Machines 发布了一种名为「交互模型」的新型架构。该模型能原生、持续地接收音频、视频和文本等多模态输入,并实时思考与响应,而非通过 Agent 串联多个独立模型。
这里的关键词是**「原生」和「持续」**。
——不是先 ASR 转文字,然后送 LLM,再 TTS 转语音的管道式处理。 ——不是把视觉、听觉、文本三个模型拼在一起,由调度器轮流唤醒。 ——而是一个统一的、持续运转的模型,能同时看、听、读、想、说。
200 毫秒:为什么是这个数字
如果只用一个数字来概括 Thinking Machines 的架构哲学,那就是:200ms。
报告提到,交互模型的前台部分以 200 毫秒为节点处理输入。这个数字不是随便选的。
人类对话中的「插话延迟」大约在 200-300 毫秒。超过这个窗口,听众就会感到「卡顿」或「迟滞」。这是电话通信领域积累了几十年的结论——ITU-T G.114 标准建议端到端延迟不超过 150ms 才能保证「自然」的对话体验。
Thinking Machines 把模型的响应节拍定在 200ms,意味着:
- 延迟必须低于人类感知阈值——用户不会察觉「它在等我」
- 上下文不能断——模型始终保持「在场」状态,不会每次重新加载
- 随时可以打断——用户的插话不会被当成新的独立请求,而是当前对话流的一部分
这一点在演示中被重点强调:用户可以在模型说话的任何时刻打断它,它会即时调整自己的输出。
这不是语音助手的「Wake Word + 单次查询」模式。这是一个始终在线、始终聆听、始终思考的交互同伴。
双引擎架构:前台 vs 后台
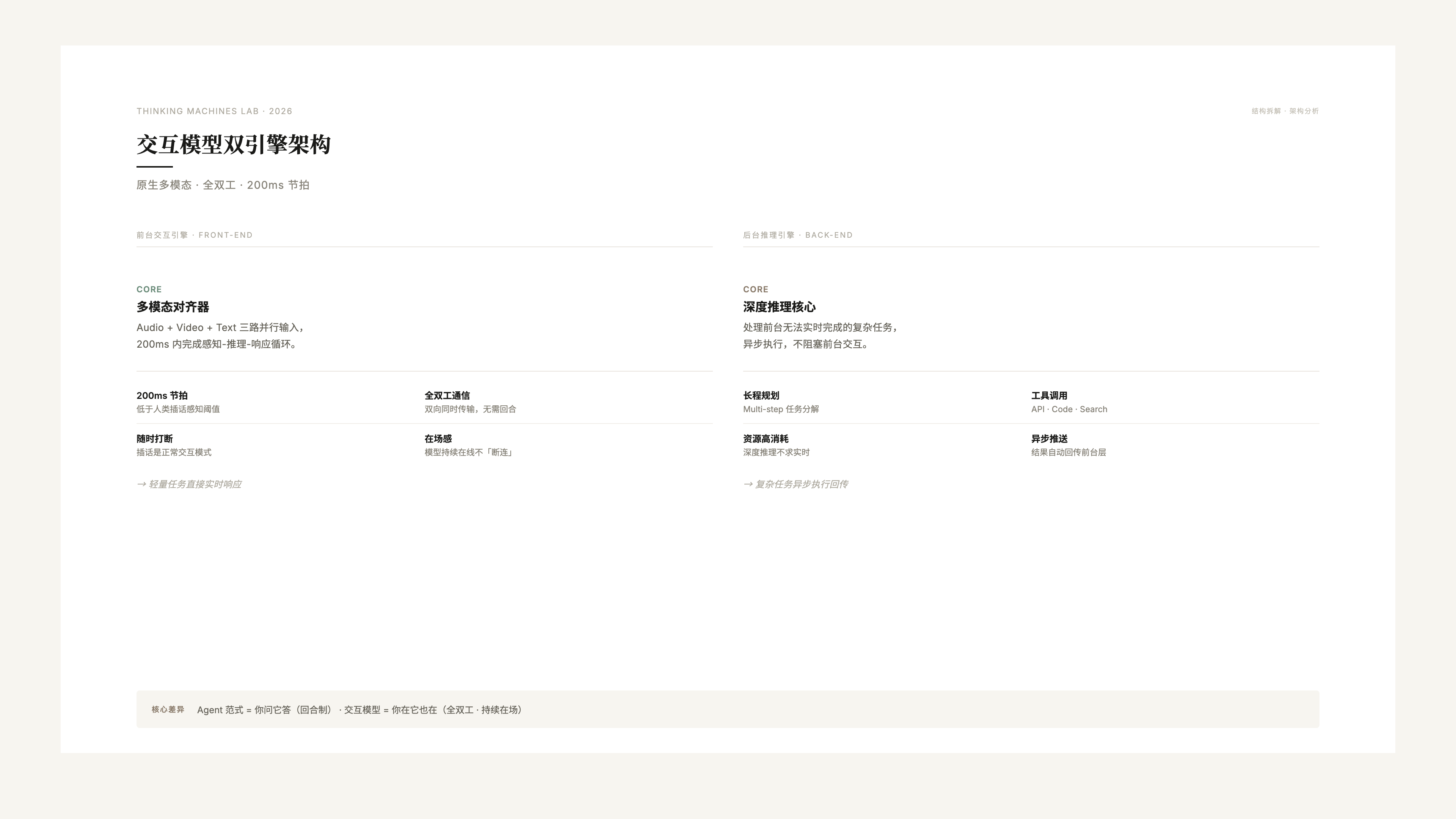
从报道的细节推断,Thinking Machines 的交互模型采用了双引擎(Two-Engine)架构:
前台交互引擎(Front-end Interaction Engine)
- 负责实时处理多模态输入(音频、视频、文本)
- 200ms 的响应节拍
- 维持用户「在场感」——知道对方仍然在、在听、在理解
- 支持随时打断和话题跳转
- 轻量、低延迟、高吞吐
后台推理引擎(Back-end Reasoning Engine)
- 处理长程规划、工具调用、复杂推理
- 不需要维持实时响应节拍
- 可以与前台异步协作
- 处理需要深度思考的任务
这两个引擎协同工作:前台维持交互的连续性和自然感,后台在必要时接手深度推理。用户最终看到的是一个统一的界面——既可以实时聊天,也可以处理重度任务。
| 特性 | 前台引擎 | 后台引擎 |
|---|---|---|
| 响应时间 | 200ms | 数秒到数分钟 |
| 处理能力 | 轻量推理、模态对齐 | 复杂推理、规划、工具调用 |
| 输入类型 | 音频、视频、文本(低延迟流) | 文本、结构化数据 |
| 交互特性 | 全双工、随时打断、在场感 | 异步、深度思考 |
| 资源消耗 | 低 | 高 |
这跟 Agent 范式有什么本质不同?
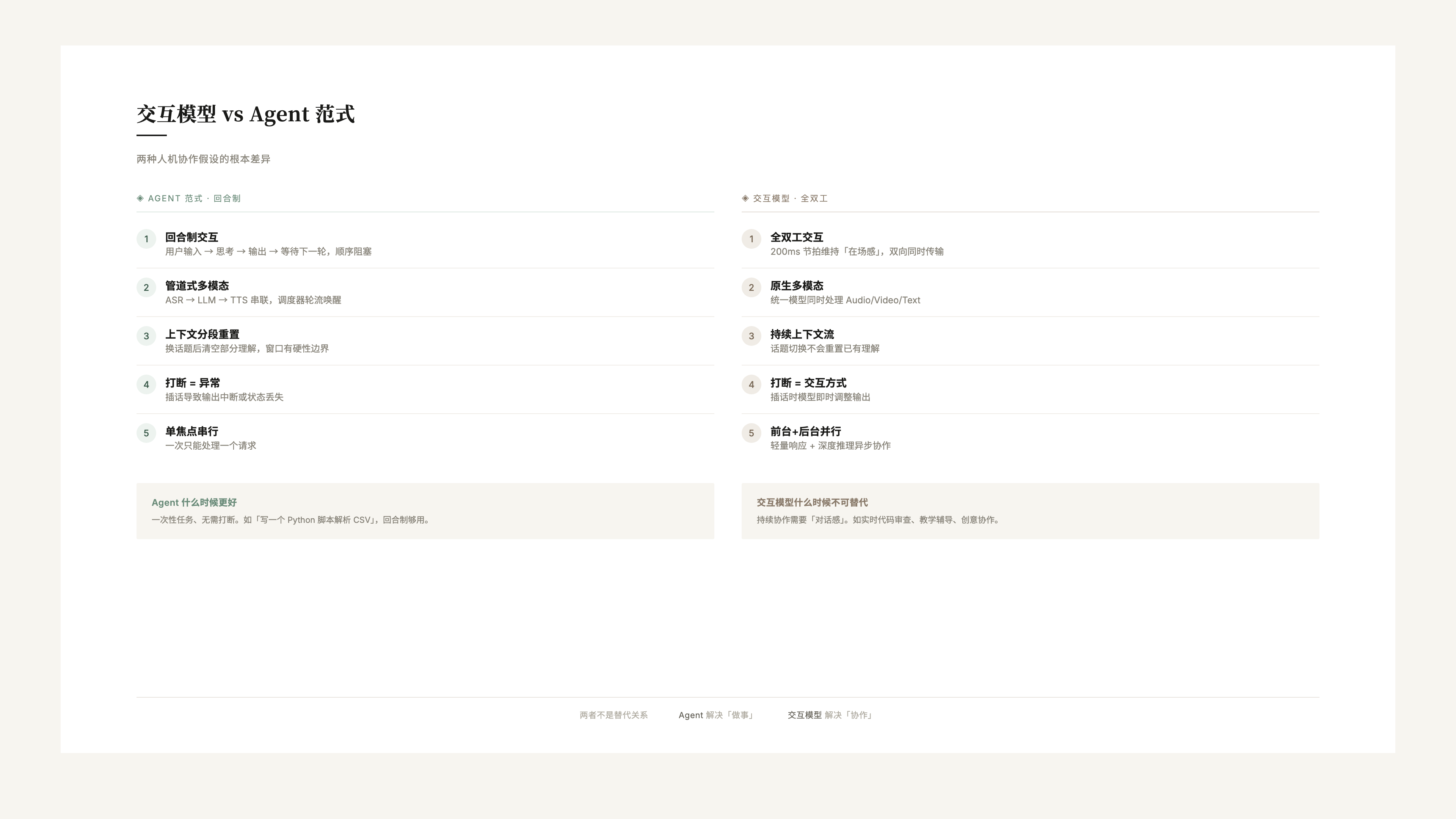
这是整件事最容易被误解的地方。很多人看到「交互模型」的第一反应是:「这不就是一个更好的语音助手/Agent 框架吗?」
不是。两者的底层假设完全不同。
Agent 范式的假设
今天的 Agent 系统(包括 Cursor 的 Agent Mode、Claude Code、AutoGPT 等)本质上仍然是回合制 + 管道式的:
- 用户输入 → 2. 模型思考 → 3. 模型输出 → 4. 模型调用工具 → 5. 等待结果 → 6. 继续思考 → 7. 输出结果
每一步都是顺序的、阻塞的、回合制的。即使是最先进的 Agent 系统,也只是把「回合」的粒度做得更细,没有改变交互的基本结构。
交互模型的假设
Thinking Machines 的交互模型假设一个完全不同的基础:
交互是持续的流,而不是离散的回合。
这意味着:
- 多模态输入是并行的——模型同时在看你的表情、听你的语气、读你输入的文本
- 输出不是独占信道——模型可以在你说话的同时«嗯»一声表示理解
- 上下文没有「重置」——不会因为你换了一个话题或模式就清空之前的理解
- 打断是交互的一部分——不是异常情况,而是正常交互模式
一个思想实验
想象你在用 Cursor 写代码。当前的模式是:你输入需求,它思考几秒,生成代码,你审查,再提修改意见。
交互模型版本的 Cursor 会是这样:
你开始打字,模型看着你的光标移动,「嗯」一声表示它理解了上下文。你停下来想了想,它说「你是不是在想那个缓存问题?我已经看了你的 Redis 配置,有两个建议……」你听到一半,说「等一下,先看看这个函数的签名」,它立刻切过去,同时把刚才的建议记在后台。
这不是「更快版本的 Agent」,这是一种全新的交互契约。
为什么现在才出现?
如果交互模型这么好,为什么之前没人做?
三个原因:
1. 计算效率的限制
全双工交互意味着模型一直在运行——不像回合制那样只在用户输入后才激活。这带来了巨大的计算开销。只有在推理成本下降到一定水平、且硬件能效比足够高之后,这种「始终在线」的模式才在经济上可行。
Thinking Machines 与 NVIDIA 的千兆瓦级战略合作恰好服务于这个需求。
2. 多模态对齐的难度
让一个模型同时处理音频、视频和文本不是简单的「把三个 encoder 拼在一起」。真正困难的不是各自理解,而是跨模态的对齐——听懂语调的同时看懂表情,在看图表的同时理解语音说明。这需要极高质量的 paired training data 和精心设计的架构。
3. 交互设计思维的缺失
最重要的原因可能不是技术层面的。整个 AI 行业在过去两年被「Chat 界面」锁死了想象空间。当每一个新产品的示例如下都是「打开对话框→输入问题→等待回答」时,很少有人停下来问:这个交互范式本身是不是该被重新设计了?
Thinking Machines 有几位核心成员本身就是 OpenAI ChatGPT 团队的骨干。他们从零开始做了一个 ChatGPT,又选择离开去做一个「不是 ChatGPT」的东西——这个选择本身就值得深思。
我的判断
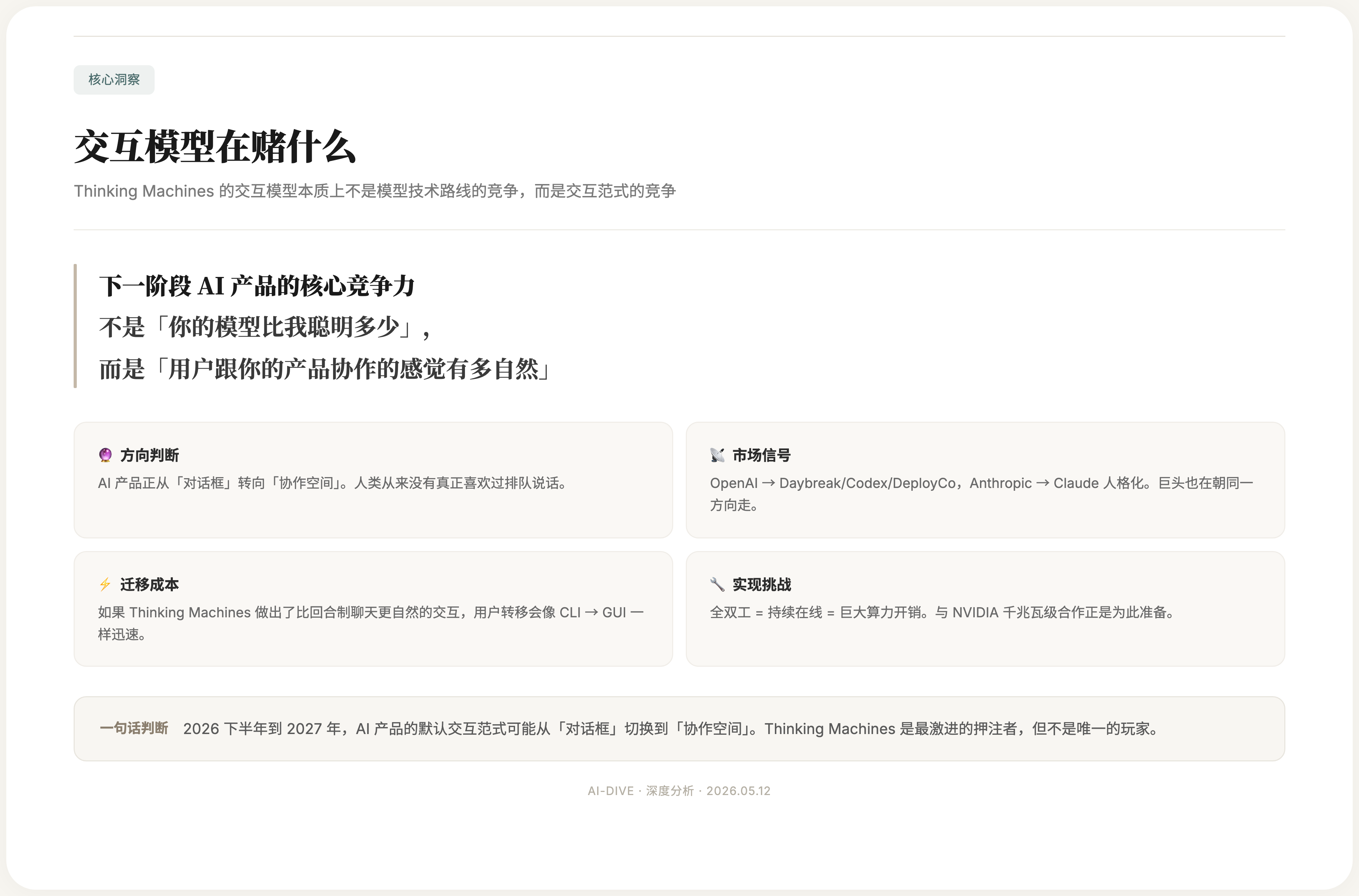
Thinking Machines 的交互模型本质上不是模型技术路线的竞争(虽然他们也发布了自有模型),而是交互范式的竞争。
它在赌一件事:下一阶段 AI 产品的核心竞争力不是「你的模型比我聪明多少」,而是「用户跟你的产品协作的感觉有多自然」。
这个判断对不对?很难说。但有几个信号值得注意:
- OpenAI 也意识到这个问题了——Daybreak、Codex 插件、DeployCo 等一系列动作显示,OpenAI 也在从「模型 API 公司」转向「交互平台公司」
- Claude 的人格化趋势——Ethan Mollick 今天的另一条信号指出,Claude 的人名、训练方式和哲学理念让它在长期交互中形成了独特的人格粘性,这与 Thinking Machines 强调的「持续在场感」方向一致
- 交互范式的迁移成本极高——如果 Thinking Machines 真的做出了一种比回合制聊天显著更自然的交互方式,用户习惯的转移会非常迅速,就像从命令行到 GUI 的迁移一样
最终,2026 年下半年到 2027 年,我们可能会看到 AI 产品从「对话框」全面转向「协作空间」。这不是技术预测——这是交互设计的必然。
毕竟,人类从来没有真正喜欢过「排队说话」。
来源:归藏 on X、Thinking Machines Lab 官方信息、CNBC / The Information / TechCrunch 综合报道