Scout:把公司知识拆成 Context Provider,让一个 Agent 长成「公司脑」
Scout 不是另一个 RAG agent,而是一个公司脑 runtime。它把 web、Slack、Drive、CRM、wiki 拆成 context provider,选 navigation over search,用三层 eval 锁定行为。源码证明它不是概念,是可运行的产品。
Scout 的 README 第一段就挑明了它的定位:
"YC's Summer 2026 RFS named 'Company Brain' and 'AI Operating System for Companies' — the same idea from two angles: pull knowledge out of fragmented sources and turn it into something AI can act on."
这不是在做一个更好的聊天机器人。这是在做一个能把公司里所有信息源(Slack、Drive、wiki、CRM、Web、MCP)变成 AI 可操作层的 runtime。
而且它已经能跑了——459 stars、42 forks、Apache-2.0、Python,2 月创建,仍在活跃迭代。虽然 0 releases / 0 tags,但 2 个 open PR(Gmail/Calendar 和 prompt 优化)说明它正在从 pre-1.0 进入功能加速期。
这篇文章从源码出发,拆解 Scout 的四个核心引擎:为什么选 navigation over search、provider 如何把复杂度关在门外、安全边界怎么设计的、eval loop 怎么收敛行为。
一、不是更大的聊天框,而是更薄的路由层
大多数 AI 知识产品在做同一件事:把公司文档塞进一个 vector store,然后指望 embedding 的语义相似度兜住一切。Scout 选了完全相反的路。
它的核心设计可以压缩成一句话:
Scout 不做知识存储,只做 source routing。
每条用户问题进来,Scout 不先去检索 embedding,而是先判断:这个问题该去哪个 source 找?Slack 还是 wiki?CRM 还是 web? 然后像代码 agent 一样——ls、grep、打开文件、跟着 import 走——用 source 自己的规则去导航。
这套设计解决了一个隐性但更本质的问题:公司知识不是一种数据。Slack 是对话流;Drive 是文档流;CRM 是结构化状态;wiki 是可沉淀的 prose;MCP 是外部系统。强行统一成一种格式,等于放弃每个 source 最擅长的能力。
这也是 "navigation over search" 的核心论点:代码 agent 从来不把整个代码库切碎嵌入再召回,它们 navigate。Scout 只是把这个模式从代码扩展到了公司知识。
二、源码层拆解:四个关键设计
1. Agent 层设计得很薄
scout/agent.py 只有 56 行。核心是一个 agno.Agent,框架来自 Agno(同一团队的自研框架)。最关键的设计是 scout_tools 是一个 callable(可调用对象),每次 agent 循环都会重新求值:
# scout/agent.py — 核心 agent 工厂
def get_scout_agent(user_id: UUID, session_id: str | None = None):
tools = partial(scout_tools, user_id=user_id, session_id=session_id)
return Agent(
name="Scout",
tools=[tools], # cache_callables=False — 每次循环重新展开工具
instructions=SCOUT_INSTRUCTIONS,
...
)
这个设计的好处是:
- 工具集是动态的——providers 可以随时增减,agent 不需要重新配置
- 每个循环都拿到最新状态——比如某些 provider 懒加载、条件挂载,不会在 session 启动时就冻结
- 一次 LLM 调用一轮——不堆多层 agent 嵌套,避免 token 膨胀和延迟累积
- 方便测试——eval 可以自由替换 provider 和行为
2. Context Provider 把复杂度关在门外
scout/contexts.py 是 Scout 最核心的 245 行代码。它维护了一个全局 ContextRegistry,每种 provider 一个实例:
# scout/contexts.py — ContextProvider 基类实现
class ContextProvider(ABC):
@abstractmethod
async def get_tools(self, ...) -> list[dict]:
"""返回 query_<source> / update_<source> 等工具定义"""
async def aquery(self, ...): ... # 异步查询
async def astatus(self, ...): ... # 健康状态
每个 provider 暴露 2 个自然语言工具:query_<source>(读)和 update_<source>(写,按需)。Scout 自己永远看不到 provider 内部的实现细节——分页、鉴权、错误恢复、线程上下文——这些都是 provider 自己的事。
目前支持的 provider:
- WebContextProvider — 常驻,用 Parallel SDK 或 MCP 做网页搜索
- WorkspaceContextProvider — 常驻,访问 Scout 自己的代码库
- DatabaseContextProvider — 常驻,CRM:contacts/projects/notes/followups
- WikiContextProvider × 2 — 常驻,knowledge(可沉淀的 prose)+ voice(风格指南)
- SlackContextProvider — 条件挂载(有 SLACK_BOT_TOKEN 才激活)
- GDriveContextProvider — 条件挂载(有 Google 服务账号)
- MCPContextProvider — 条件挂载(按注册列表)
Registry 还处理了去重 ID、懒加载、实时状态查询——这些都是一个生产级 provider 系统需要的基础设施。
3. 安全边界不是装饰,是代码级保障
很多 AI agent 只在 prompt 里写 "don't modify the database"。Scout 在编译层面做了两层防护。
db/session.py 设计了 2 个引擎:
# db/session.py — 双引擎安全设计
readonly_engine = create_async_engine(... , connect_args={
"options": "-c default_transaction_read_only=on"
}) # PostgreSQL 级别只读
SQL 引擎带 schema guard 钩子
@event.listens_for(sql_engine.sync_engine, "before_cursor_execute")
def reject_dangerous_schemas(...):
if any(schema in statement for schema in ["public.", "ai.", ...]):
raise_schema_error(...) # 写入非 scout schema 直接拒绝
这意味着:
- 读路径:走 Postgres 原生只读事务,数据库层保证不产生写操作
- 写路径:只能落在
scoutschema 内(contacts、projects、notes),任何试图写入public或aischema 的 SQL 都被before_cursor_execute钩子拦截 - Knowledge wiki:如果配置了 Git backend,每次
update_knowledge变成一次可审计的 commit/push——不是改了一个文件就完事,而是留下了完整的版本历史
这套设计的价值在于:安全不依赖 prompt 的"听话程度",而是代码级的结构约束。
4. Eval Loop 不是装饰,是质量基线
docs/EVALS.md 和 evals/ 目录(~1200 行代码)把评测分成了三层:
- Wiring:9 个代码级检查(W1-W9),不调用 LLM。验证工具形状、schema guard 存在、provider 协议实现、MCP 生命周期、默认 user_id 等基础设施完整性
- Behavioral:25+ 测试用例,覆盖 multi-turn、tool assertion、followups 链式调用。每个 case 可以在 16 种 fixture 组合下运行
- Judges:7 个 LLM 评分的质保案例(0-10 rubric 评分),用 LLM-as-judge 评估 Scout 的输出质量
三层之间还有一个 live-container loop——在持续运行中反复触发这些检查,形成闭环收敛。
这个设计的隐藏价值是:Scout 可以在不读 prompt 的情况下,通过 wiring 检查确保基础设施没问题,通过 behavioral 检查确保 routing 正确,通过 judges 确保输出质量。这比堆更多 prompt 更可靠。
三、架构总览
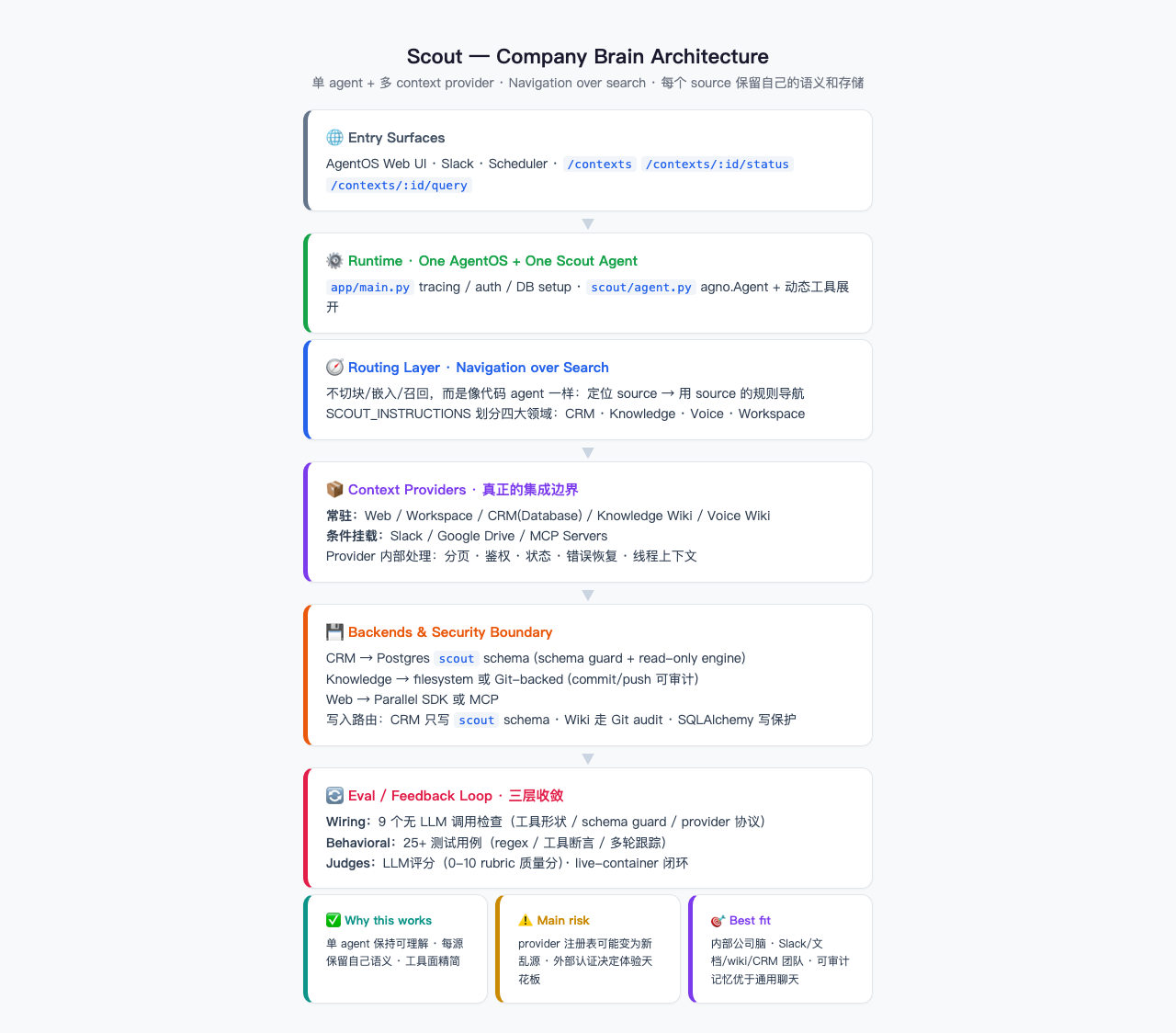
主线链路很短:
- 入口(Web UI / Slack / Scheduler)→
- AgentOS runtime(tracing、auth、session)→
- Scout Agent 接收请求 →
- 定位 source(navigation over search)→
- Provider 处理具体查询 →
- Backend 返回结果 →
- Eval loop 持续收敛质量
四、六段式深度分析
1. 项目概览
Scout 是 Agno 做的开源公司脑(Company Intelligence Agent),定位在 "AI Operating System for Companies"。不是 RAG,不是聊天机器人,而是一个能把 Slack、Drive、wiki、CRM、Web 和 MCP 串起来的 company brain runtime。
它不是在概念阶段——源码完全可读、可跑、可部署(Docker / Railway),2 replica 零宕机部署方案已经写好了。
阶段判断:pre-1.0 可运行产品原型,正在从「能跑」向「生态」过渡。
2. 架构拆解
架构的核心不是 agent 本身,而是 agent 和 provider 之间的边界:
- Scout 很薄(56 行 agent):只做 routing,不知道任何 source 的协议细节
- Provider 很厚(每个 provider 独立处理鉴权/分页/错误恢复)
- 入口层:Web UI / Slack / Scheduler 统一进 AgentOS
- Runtime 层:AgentOS 处理 tracing、auth、session、database
- Routing 层:navigation over search,四大领域划分(CRM/Knowledge/Voice/Workspace)
- Provider 层:常驻 + 条件挂载,去重懒加载
- Storage 层:CRM(Postgres schema guard)/ Knowledge(filesystem 或 Git)/ Web(MCP)
- Eval 层:wiring / behavioral / judges 三层闭环
3. 核心机制
除已详述的四个引擎外,还有几个值得关注的实现细节:
- Schema-on-demand CRM:
db/tables.py的 canonical DDL(contacts、projects、notes、followups)不是完整的业务模型,而是 agent 可以自然生长的瘦 schema。Scout 可以在运行时动态扩展scout_coffee_orders这样的新表 - Git-backed 知识库:WIKI_REPO_URL + WIKI_GITHUB_TOKEN 即可启用,无需改代码。commit/rebase/push 提供了完整的审计链
- 条件挂载:Slack、Drive、MCP provider 只有在对应凭证存在时才激活,避免了不必要的 API 调用和错误处理
- JWT 认证:生产环境默认启用 AgentOS 的 token-based authorization,不配置 JWT 密钥则拒绝所有请求——这是一种"安全优先"的部署策略
4. 优势与不足
| 维度 | 优势 | 不足 / 风险 |
|---|---|---|
| 产品定位 | "公司脑"叙事清晰,不是泛 agent,是场景化的 runtime | 目标太大,provider 增多后边界容易膨胀 |
| 架构 | 单 agent + provider 抽象,主线干净 | 依赖 Agno 框架(同一团队),存在 vendor lock-in 风险 |
| 安全 | Postgres schema guard + 只读引擎 + Git audit trail,代码级保障 | 外部 auth / backend 质量仍是系统上限 |
| 可靠性 | eval 三层收敛 + live-container loop,比堆 prompt 更稳 | 25+ behavioral cases 对于生产级 agent 还不够 |
| 生态 | Slack / Drive / wiki / CRM 覆盖了企业 80% 的知识源 | 0 releases / 0 tags,Gmail/Calendar 还在 PR 阶段 |
| 增长 | 459 stars,2 月创建,仍在更新 | 社区规模小,没有持续的第三方贡献 |
5. 适合谁
最适合:
- 需要在 Slack/docs/CRM/wiki 之间串统一工作流的团队
- 在做内部 company brain / knowledge OS 的产品团队
- 想研究「单 agent + source routing」而不是「多 agent 编队」的架构师
- 对 AI 写入安全性有严格要求的团队(Scout 的 schema guard + read-only engine 是生产级方案)
不太适合:
- 只想搭一个简单问答机器人
- 没有 Slack / Drive / CRM / wiki 等真实信息源
- 依赖成熟 release 周期和社区支持
6. 我的判断
Scout 是当前开源领域最接近「公司脑」定义的项目。不是因为它的 README 写得漂亮,而是因为源码里的架构选择确实对齐了这个目标。
几个值得 mark 的工程决策:
- 选 navigation over search——这和当前 AI agent 技术栈的主流方向(Agentic RAG、multi-hop retrieval)形成对比。它赌的是「公司知识不适合统一索引」这个判断,从源码层面看这个判断站得住
- 代码级安全而非 prompt 级安全——schema guard + read-only engine 是当前大多数开源 agent 项目完全忽略的工程细节
- Eval 三层的选择——wiring/behavioral/judges 的分层设计说明团队有系统工程背景,不是把 agent 丢到生产环境就完事
最大的不确定性是 Agno 框架的生态独立性。Scout 深度依赖 Agno(同一团队),如果 Agno 的迭代方向发生变化,Scout 的兼容性成本会很高。
整体结论:值得关注,适合作为公司脑架构参考,但不建议在现阶段直接作为生产依赖。 如果后续能看到稳定的 release 节奏和更多的社区 provider 贡献,它会是很有代表性的 internal agent runtime。