Crab:提升Agent沙箱恢复正确率从8%到100%的语义感知C/R运行时
Agent沙箱的checkpoint/restore面临尴尬局面:轻量恢复正确率不到10%,全量checkpoint在密集部署下慢3-4倍。香港科大Crab用eBPF追踪OS副作用,只对真正有状态变化的交互步做checkpoint,恢复正确率100%,额外延迟不到1.9%。
一句话总结
Agent 沙箱的 checkpoint/restore 面临一个尴尬局面:轻量恢复(只保对话)正确率不到 10%,全量每步 checkpoint 在密集部署下又慢 3-4 倍。香港科大的 Crab 系统用一个简单洞察解决了这个矛盾——75% 的 Agent 交互步根本没有产生值得恢复的状态——通过 eBPF 追踪 OS 侧的真实副作用,只对"真的变了"的东西做 checkpoint,恢复正确率提到 100%,额外延迟不到 1.9%。
一个问题
想象一下:你的 Agent 跑了 200 步,编译了代码、装了依赖、启动了一个后台服务,突然 crash 了。系统告诉你"对话已经恢复",但重启后发现编译器没装、服务没启动、依赖的配置文件还在旧版本。这就是目前主流 Agent 平台的常态。
反过来,如果你要求每一步都完整保存整个沙箱状态——文件系统、进程、内存——那在 100 个沙箱共享一台机器时,I/O 带宽会成为瓶颈,任务慢上好几倍。
两种都不行。知识不在对话里,在 OS 里;但 OS 不知道哪些状态值得保存。
香港科技大学的研究团队把这叫做 Agent-OS 语义鸿沟,并提出了一个解决系统——Crab。
两个极端都不对
先看数据。
论文在 Terminal-Bench(shell 密集型任务)和 SWE-Bench(代码修复)上做了实验。
| 恢复策略 | Terminal-Bench 正确率 | SWE-Bench 正确率 |
|---|---|---|
| 仅恢复对话 | 8-13% | 9% |
| 对话+文件系统 | 28-42% | 100% |
| 从零重跑 | 100% | 100% |
| 每步全量 checkpoint | 100% | 100% |
| Crab(自适应) | 100% | 100% |
仅恢复对话不行——进程状态丢了。对话+文件系统在 Terminal-Bench 上也不够——有些任务依赖后台进程或已安装的软件包。全量 checkpoint 正确,但代价很高:96 个沙箱时,每步全量 checkpoint 比无故障基线慢 3.78 倍。
关键洞察:75% 的 Agent 交互步不产生任何有价值的 OS 状态变化。 大部分操作是读文件、查信息、简单计算——这些不需要 checkpoint。
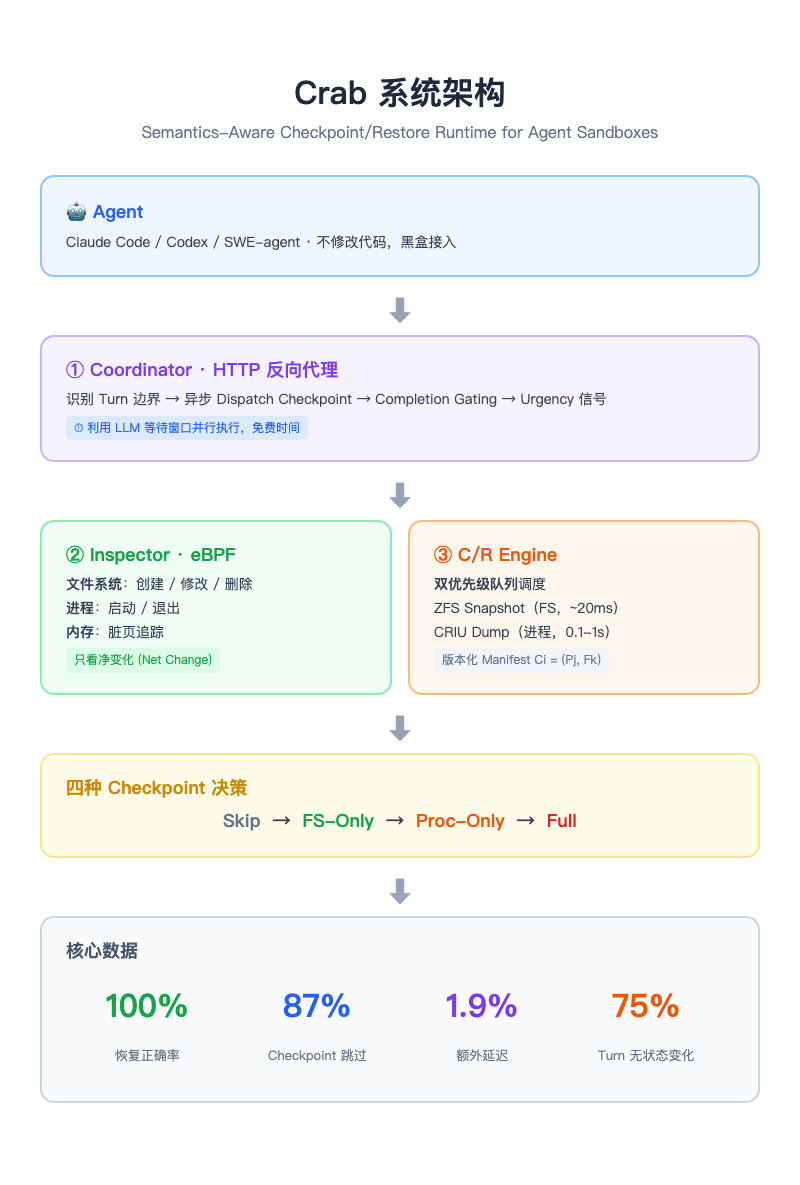
三元架构
Crab 不修改 Agent 代码,不换 C/R 后端,只在一个地方动手:宿主侧的 HTTP 代理。
三个组件,三层分工:
① Coordinator——看门的
以一个 HTTP 反向代理的身份插在 Agent 和 LLM 之间。Agent 每次调用完工具、等待 LLM 回复的时刻,就是一次 checkpoint 窗口。Coordinator 在这个窗口里做四件事:识别 turn 边界、查询是否要 checkpoint、提交任务、LLM 回复回来后如果 checkpoint 没完成就挡住。
关键:LLM 思考时间就是免费时间。Agent 平均每次等 LLM 回复需要几秒钟,Crab 用这段时间并行做 checkpoint,大部分情况下用户完全感知不到。
② Inspector——嗅探的
一个基于 eBPF 的轻量级内核监控器。每个 Agent turn 完成后,它检查三件事:
- 文件系统:有没有文件被创建、修改、删除?
- 进程:有没有新进程启动或旧进程退出?
- 内存:还在运行的进程有没有写脏页?
重要的是,它只看净变化(net change)——如果你在一个 turn 里创建了一个文件又删掉,Inspector 知道这不需要 checkpoint。精度:100% 检出率(零假阴性),2.3% 的假阳性只会触发一次廉价的文件系统快照(~20ms)。
③ C/R Engine——执行者
拿到 Inspector 的判断后,决定是跳过不做、做文件系统快照(ZFS,~20ms)、做进程快照(CRIU,0.1-1s)、还是两者都做。
Engine 有两个优先级队列。如果 LLM 已经回复了但 checkpoint 还没完成,自动晋升到高优先级,保证不会让 Agent 空等。
数据说话
论文的实验非常扎实。3 种 Agent(Claude Code、iFlow-cli、SWE-agent)、2 个 benchmark、4 种对比基线、密度从 16 到 96 个沙箱。
恢复正确率(含一次随机 crash)
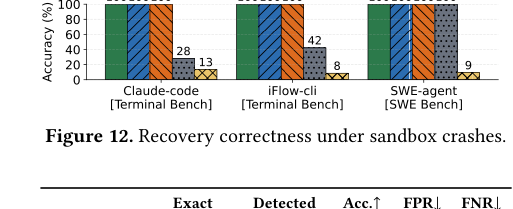
Crab 在所有设置下都达到 100%。
端到端延迟(含一次 crash vs 无故障基线)
| 密度 | Crab 额外延迟 | Restart(重跑) | FullCkpt(每步全量) |
|---|---|---|---|
| 16 | < 0.9% | +60% | 接近 0 |
| 32 | < 1.9% | +60% | +47% |
| 64 | < 1.9% | +68% | +3.06× |
| 96 | < 1.9% | +67% | +3.78× |
Checkpoint 稀疏性
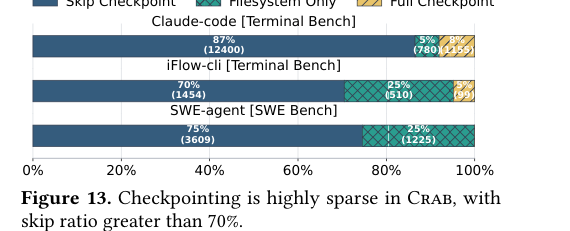
| Workload | 跳过(无操作) | 仅文件系统 | 完整 checkpoint |
|---|---|---|---|
| Claude Code (Terminal) | 87% | 5% | 8% |
| iFlow-cli (Terminal) | 70% | 25% | 5% |
| SWE-agent (SWE) | 75% | 25% | 几乎 0 |
这就是 Crab 的秘诀:绝大多数 turn 不需要 checkpoint,而真正需要的时候,也只做最小必要的事。
更多玩法
Crab 不只是被动容错。论文展示了四种实际用途:
1. Agent 主动回滚。 把 rollback 以 API 形式暴露给 Agent,代替脆弱的 shell 级自我修复。一个 QEMU 启动任务,Agent 本来花了大量步骤做清理(信号量 9 kill 杀不掉进程),用 rollback API 直接从 checkpoint 恢复,耗时降低 29%。
2. 抢占实例。 云上 spot 实例被回收前给 60 秒通知。Crab 在 1 秒内完成 checkpoint + 迁移,即使被抢占 5 次也只增加 3% 的任务时间。
3. 推测执行。 用小模型先走一步,大模型验证。如果一致,跳过验证。Crab fork 沙箱做并行,比基线快 7.9%。
4. RL 后训练加速。 Tree GRPO 需要在中间节点 fork 出多个分支。Crab 让后续分支直接从中间 checkpoint 开始,而不是重新执行公用前缀,token 减少 40-64%。
判断
Crab 不是炫技论文,而是一个工程上可以直接落地的系统。三件事值得关注:
-
洞察简单,效果惊人。 "75% 的 turn 不需要 checkpoint"这个数据在任何 Agent 部署中被低估了。它意味着很多 per-turn 的基础设施操作都可以按同样逻辑优化——审计、追踪、计费、Profiling。
-
eBPF 的 net-change 思路可推广。 不只是 C/R,同样的"观察 OS 净副作用"的思路可以用在 GPU 资源审计、容器配额管理、Agent 行为安全审计上。
-
设计决策务实。 不修改 Agent、不换后端、只加一个 HTTP proxy——这个架构让它很容易嵌入现有平台。
对于正在做 Agent 基础设施的团队(如 E2B、OpenHands、以及任何跑密集 Agent 沙箱的平台),Crab 是一个可以直接参考实现的系统。