Scout:单 agent 通过 Context Provider 长成“公司脑”
Scout 不是更大的聊天机器人,而是把 web、Slack、Drive、CRM、wiki 和 MCP 拆成 context provider 的单 agent runtime。
Scout:单 agent 通过 Context Provider 长成“公司脑”
Scout 不是在做一个更大的聊天框,而是在做一层更薄的“公司路由层”。它把 web、Slack、Drive、wiki、CRM 和 MCP 服务拆成一组 context provider,让一个单 agent 通过统一的 query_* / update_* 入口去读写不同来源。这个方向的价值不在“回答得更像人”,而在“把公司知识和公司动作变成可持续运行的系统”。
从 GitHub 信号看,这个项目已经有了相当完整的产品骨架:316 stars、28 forks、Apache-2.0、Python、最近一天内仍有更新,但还没有 release/tag,说明它更像一个正在快速打磨的 pre-1.0 runtime,而不是已经冻结的成熟平台。
背景:公司脑为什么难做
公司知识不是一种数据,而是很多种:
- Slack 是对话流
- Drive 是文档流
- CRM 是结构化状态
- wiki 是可沉淀的 prose
- MCP 是外部系统
把这些东西全都塞进一个 vector store,表面上很统一,实际上会把权限、分页、写入、审计和失败恢复一起糊成一团。Scout 选择反过来做:先承认异构,再用 provider 统一入口。
核心问题:Scout 到底在解决什么
它解决的不是“能不能搜到内容”,而是三个更实际的问题:
- 该去哪个源找
- 找到后怎么安全读写
- 如何把知识沉淀成可审计的长期记忆
这也是它和普通 RAG / 普通 agent 的分界线。Scout 更像一个 source-routing runtime,而不是单纯的生成式前端。
架构拆解
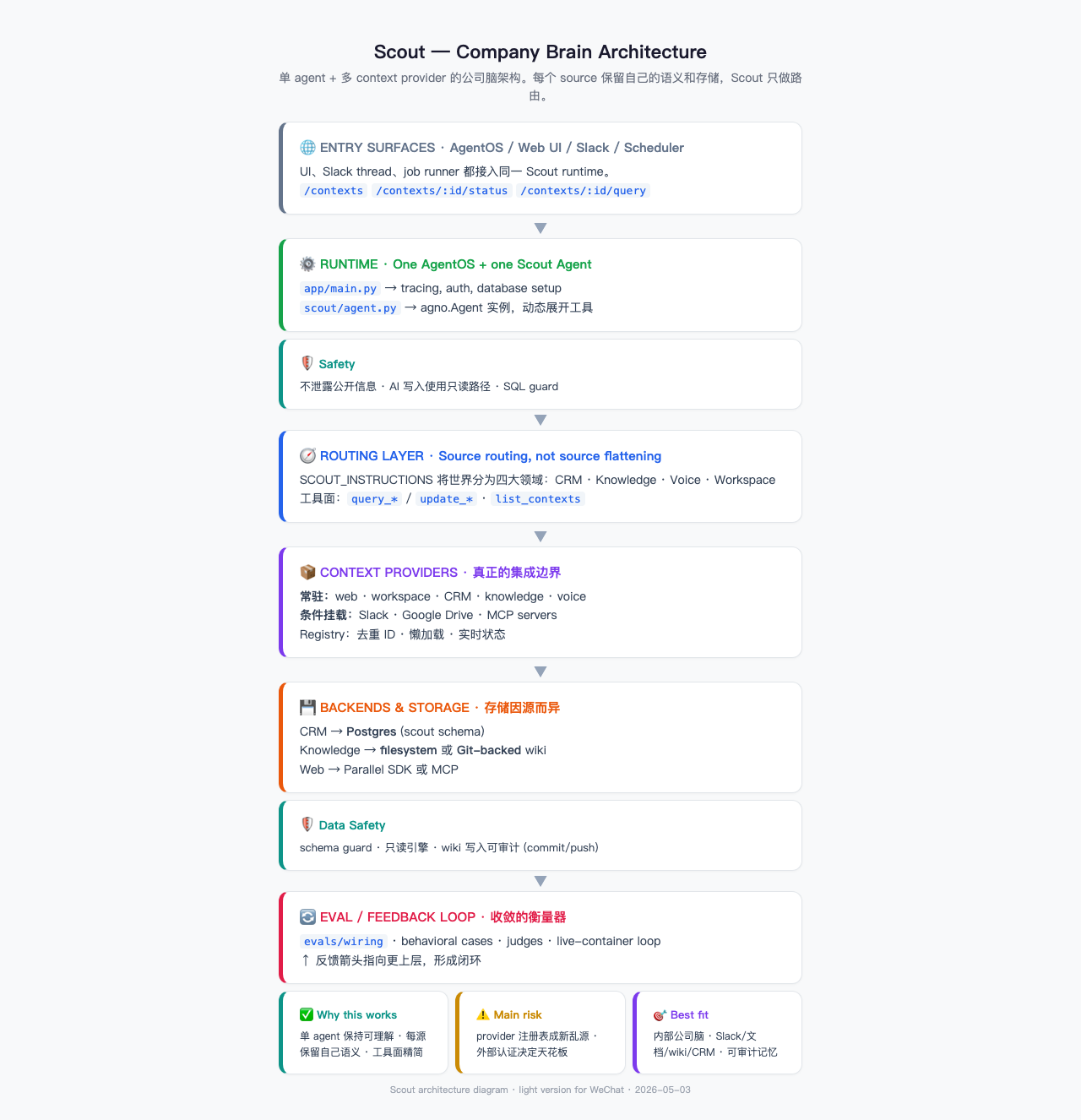
最关键的主链路很短:
- 用户从 Web UI、Slack 或调度任务进来
- AgentOS 负责授权、tracing、session 和 scheduler
- Scout Agent 接收请求,按 instructions 选择路由
- context registry 动态展开当前可用的 provider
- provider 再去访问自己的 backend:Postgres、Git wiki、文件系统、外部 API
- 结果回流给 Scout,再输出答案或执行动作
几个关键实现点很能说明问题:
app/main.py是 AgentOS 入口,startup 时先建表,再 setup providerscout/agent.py只有一个 Scout agent,但工具是按当前 provider 动态展开的scout/contexts.py负责 registry:web、workspace、CRM、knowledge、voice 是常驻,Slack、Drive、MCP 是条件挂载db/session.py和db/tables.py把 CRM 的写入锁在scoutschema 里,同时再加一层 SQL guard 和 read-only enginedocs/EVALS.md把 wiring / behavioral / judges / live-container 四层评测都补上了
核心机制:它为什么比“一个大工具箱”更稳
Scout 的主设计其实就一句话:把复杂度关进 provider,把 Scout 保持得尽量薄。
1) Navigation over search
README 里直接写了 “Navigation over search”。这不是口号,而是产品路线:
- 不是先把所有文档切块、嵌入、召回
- 而是像代码 agent 一样先定位 source,再用 source 的规则去导航
这很适合公司语境,因为公司里的 source 本来就不是同一种东西。
2) Context provider 是真正的边界
Scout 自己看到的只是工具名;provider 才知道怎么处理:
- Slack thread 还是 channel
- Drive 是 shared drive 还是普通文件夹
- wiki 是文件系统还是 Git-backed
- CRM 是读还是写
- MCP 是 stdio / SSE / streamable HTTP
这类抽象的好处是,Scout 的主提示词不用学习每个系统的全部协议细节。
3) 读写分离不是装饰,是安全边界
CRM 这条链路尤其值得看:
- 读路径走 read-only engine
- 写路径只能落在
scoutschema - 还有 SQLAlchemy 层的写保护
这意味着就算 prompt 里出现了“顺手改表”这种危险请求,系统也不会轻易把写操作发到错误的地方。
4) Knowledge wiki 不是缓存,是持久化记忆
Scout 的知识库默认是 filesystem-backed;如果配了 Git backend,就会把 update_knowledge 变成一次可审计的 commit / push。
这点很重要:它不是“记住一段摘要”,而是把知识变成版本历史。对内部知识系统来说,这比单纯 embedding 更接近真实工作流。
5) Eval loop 是它的稳定器
它把检查分成三层:
- wiring:工具形状、SQL guard、provider 结构
- behavioral:路由和响应行为
- judges:LLM 质量评分
这种分层能把很多“看起来不错但行为漂移”的问题提前拦住。对于一个会接 Slack、Drive、CRM 的 agent runtime,这比堆更多 prompt 更重要。
优势与不足
| 维度 | 优势 | 代价 |
|---|---|---|
| 定位 | “公司脑”叙事直接,业务上容易理解 | 目标太大,边界容易膨胀 |
| 架构 | 单 agent + provider,主线干净 | provider 多了会回到 tool zoo |
| 安全 | schema guard、read-only engine、Git audit trail | 外部系统的 auth / API 稳定性仍是上限 |
| 维护 | eval 体系完整,便于持续调 routing | 需要长期维护 provider 和规则 |
| 成熟度 | 最近仍在动,说明项目活跃 | 还没有 release/tag,离稳定平台还有距离 |
Scout 最好的地方在于:它没有试图把所有东西都塞进一个统一黑盒;它承认知识来源是异构的,于是把异构保留在边界里。
但它的风险也很明显:provider 体系越成功,治理难度越高。 一旦接入源过多、规则不够清晰,新的复杂度会再次堆回 registry 和 prompt 上。
适合谁
适合:
- 已经有 Slack、wiki、CRM、Drive 这些真实系统的团队
- 想做 internal company brain / agent OS 的产品团队
- 需要可审计、可回放、可调优的长期记忆系统的人
不适合:
- 只想要一个轻量聊天机器人
- 没有真实公司数据源的人
- 没有资源维护权限、后端和 eval 的团队
我的判断
Scout 是一个方向正确、结构清楚、但还在打磨中的 company brain runtime。
如果把它放在更大的技术图谱里看:
Hermes更偏运行时和消息网关m-flow更偏路径式记忆与检索gbrain更偏长期知识层- Scout 则更偏“把公司知识和动作接到一个统一入口上”
我的结论是:值得关注,而且很适合当作公司内部 agent 架构的参考样板。 它现在不是“已经完成的产品”,但已经不是“只有想法的 demo”了。真正决定它上限的,不是模型能力,而是它能不能把 provider 边界、权限治理和 eval 收敛长期维持住。